在大多数Google Analytics(GA)或Matomo后台中,我们都能看到一类神秘的流量来源:“直接访问(Direct)”。它通常指用户未携带任何可识别来源标签,直接输入网址或通过收藏夹、浏览器书签访问页面。
但在真实世界中,这部分“直接流量”中混杂着大量“隐性SEO流量”,比如:
- 用户首次通过Google搜索进入页面,之后直接输入路径再次访问;
- 在Google搜索后,跳转至AMP页面,再回到主站;
- SERP页面点击链接但因JS重定向、跳转逻辑,来源字段丢失;
- 使用某些移动App内嵌浏览器点击搜索结果,Referer信息丢失。
这些流量明明来源于SEO,却被归因到“Direct”。
那么,问题来了:
我们该如何量化这部分“被错判的SEO流量”?
有哪些建模方法可以估算SEO在Direct流量中的真实占比?
这篇文章将给你答案:以归因模型思维为基底,结合行为路径分析、Landing Page特征识别、时间线回溯等策略,建立一套实用的“Direct流量SEO再归因模型”。
第一章:为什么Direct流量里隐藏着SEO的真实贡献?
1.1 Direct ≠ Typed URL
首先要破除一个误区:
直接流量并不等于用户输入了网址。
真实世界中的“Direct流量”往往包含:
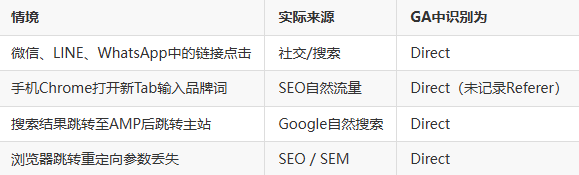
1.2 原因:搜索后的“会话劫失”问题
Referer 丢失或 Attribution 中断是主要原因:
- AMP跳转未携带完整的Referer字段;
- 使用HTTPS但跳转至HTTP页面(或不同主域)会丢失来源;
- 某些轻应用或迷你程序不传递来源;
- 用户开启隐私浏览模式,浏览器默认隐藏来源链路。
第二章:哪些页面的Direct流量,可能是SEO带来的?
我们需要判断:在所有Direct流量中,哪些访问很可能“原本是搜索来访”?
2.1 着陆页特征分析法(Landing Page Segmentation)
思路:SEO页≠Direct常见页
高潜SEO贡献页面的3大典型特征:

这类页面若出现在Direct流量中,极有可能是“伪Direct”。
2.2 首次访问 vs 回访时间差分析(Temporal Attribution)
思路:如果某个用户在首次访问时间之前3天内曾通过SEO来访,那么本次Direct流量可能是搜索引起的回访。
方法:
- 记录用户首次访问路径
- 查看是否曾在过去72小时内通过SEO渠道访问相同/相关页面
- 标记为“归因可疑”
这种方式适用于支持User ID或Client ID的分析工具(如GA4、Piwik Pro、Mixpanel)。
2.3 会话路径回溯模型(Session Chain Reattribution)
构建基于Cookie/Client ID的访问链:
Session 1: Google / Organic → Landing Page A
Session 2: Direct → Same Page A
Session 3: Direct → Homepage 根据典型AEO行为,Session 2 与 Session 3 均可归因至原始SEO来源。
优先使用归因模型中的Decay(衰减)分配法或W-shaped attribution。
第三章:三种模型化方法,估算“Direct中的SEO份额”
3.1 模型一:页面归属概率模型(Page-based SEO Probability)
将Direct访问中每个URL按照“SEO特征指数”打分:
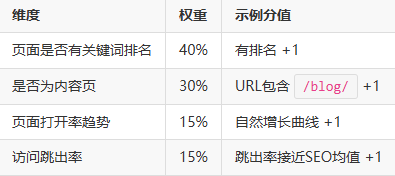
总分高于3的页面,判定其Direct流量中有**>70%概率是SEO误归因**。
3.2 模型二:行为路径回溯模型(Behavioral Reattribution Tree)
使用用户访问链路构建行为树,识别如下路径:
Google → Page A
↓
3天后
↓
Direct → Same Page A 定义回访窗口(如7天),计算从SEO访问转化为Direct访问的用户比例R,然后:
Direct中的SEO估算 = R × Direct在该页中的总访问数这可以实现分用户层的微归因建模。
3.3 模型三:历史基线偏差模型(Baseline Deviation Model)
假设:
- 该页面在SEO排名下降前,Direct比例为10%
- SEO排名下降后,Direct比例上升至30%
→ 差异20%视为“SEO被误归因的流量上浮”
使用历史时间序列模型(ARIMA、LSTM等)预测正常情况下的Direct基线值,与实际值对比得到偏差。
第四章:如何操作?完整实践步骤指南
Step 1:识别SEO典型页面库
- 从Semrush / Ahrefs / GSC中导出所有自然流量页面
- 标记URL路径、关键词覆盖、流量趋势
Step 2:对比同一URL的Direct与Organic访问占比
- GSC中查看Organic点击数据
- Google Analytics中查看Direct来源着陆页
- 计算Direct/Organic比值异常升高的页面
Step 3:建立页面归因模型,按分值分层
- 高可信:100%归因SEO(如页面仅从搜索进入)
- 中可信:70-90%归因SEO(存在关键词排名 + 路径稳定)
- 弱可信:30-50%(行为路径间接支持)
Step 4:调整SEO报告指标,加入“隐性SEO估算值”
- 原始SEO流量 = GA中Organic流量
- 补充估算SEO = 高可信SEO页中Direct流量 × 估算系数
- SEO真实流量 = 原始 + 补充
第五章:如何避免SEO流量被误归类为Direct?
5.1 避免中间跳转页面或JS重定向
- 确保搜索结果直接跳转目标URL
- 避免采用Meta Refresh或延时跳转
5.2 保持HTTPS一致性,避免跳转时丢失Referer
- 确保AMP与主站统一域名
- 避免从HTTPS跳转到HTTP
5.3 构建服务器日志追踪+Cookie辅助识别机制
- 将Referer数据存入服务器端日志
- 绑定初次访问时的来源到用户Cookie
- 用于之后Direct流量归因
第六章:案例实操——我们如何复盘被误归因的SEO份额?
背景
某客户网站为SaaS平台,2024年下半年上线内容营销模块。
观察发现:
/blog/crm-automation-setup.html页面有稳定SEO排名- 但GA中显示Direct占比高达65%
操作流程
- GSC中确认该页面过去3月有自然搜索流量
- 使用GA的Client ID跟踪,发现大量用户从Google进入该页后,3\~5天内有Direct回访行为
- 建模回溯后推断:该页面的Direct流量中有约40%-60%来源于先前的SEO访问行为
→ 最终将这部分重新归入SEO报告,客户决策更科学
结语:SEO正在被“隐身”,而你必须主动复权
在AI摘要、社交转发、嵌入式浏览器等环境下,SEO带来的流量越来越难被显性捕捉,但这不代表它不重要。
你需要:
- 主动构建“归因补偿机制”
- 深入理解“伪Direct”的形成路径
- 将SEO真实贡献复盘到决策数据中
只有这样,SEO在ROI考核、预算争取、内容评估中,才能重新“说话有分量”。