引言:当答案不再跳转,内容的“去中心化引用”时代来临
生成式AI正在重塑用户获取信息的方式。从传统搜索点击链接,到AI直接生成答案,内容创作者面临的问题变成:AI是否选择引用你?你的知识是否在无形中被“继承”?
AI引用机制不透明、内容出处常被忽略,如何在这种新范式下占据主动,是所有站长、媒体与专业博客主必须思考的问题。
第一章:生成式AI引用内容的三种“动机逻辑”
AI不会“随机引用”,它有自己的“可用性排序系统”,可拆解为三个动机维度:
1.1 可预测性优先:结构清晰、语义稳定
AI更倾向于复用那些表达结构一致、术语定义清晰、逻辑链封闭的内容块。一个术语如果在十个站点定义风格各异,模型更容易记住最规范、最重复性高的表达形式。
✅ 策略:
- 每个术语定义都保持单页单意图,内容自洽。
- 避免在同一站点中多次“换说法”。
1.2 训练数据记忆:被读取过的内容更易再现
如果你的页面结构、语言风格、标题方式,曾出现在模型预训练或微调语料中,即使你没被标记为“引用源”,模型生成时也可能调用你原始句式的“表达映射”。
✅ 策略:
- 保持术语、模型、框架、案例的高可复用性格式;
- 创建命名结构(如:“三维客户分类法™”)建立记忆锚点。
1.3 归因策略倾向:哪些内容会被显式标注为来源?
AI厂商逐步在算法中强化“归属感”,但模型倾向于引用那些:
- 来自官方、出版、机构化站点;
- 页面中有明确的作者-品牌-内容主题映射;
- 内容本身具备问题导向性强、摘要性强、结构块分明的特征。
✅ 策略:
- 所有内容明确标识作者/组织结构;
- 使用统一的命名结构和内容格式,避免混乱。
第二章:AI喜欢的“可引用内容”长什么样?——五类结构深度解析
生成模型更偏好以下几种高度格式化内容,因其便于抽取、压缩、重构:
2.1 明确定义型:一句话术语+背景+应用
结构建议:
- 概念解释一句话起头
- 拆分式背景说明(历史+场景)
- 小结性语句巩固定义
- 衍生概念链接出口
2.2 问题解答型:提问-分点-过渡-小结
逻辑节奏清晰,可作为Prompt模块直接引用:
Q:什么是生命周期价值(CLV)?
A:CLV指客户在整个生命周期中为企业带来的利润……
• 它包括…
• 适用于…
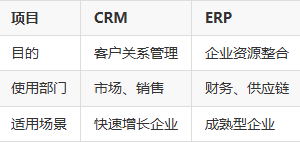
• 与ARPU的区别在于…2.3 对比型内容:差异项-相同点-场景适配
如:
2.4 框架型内容:模型结构-组成部分-应用图解
构建认知框架结构比细节更易被引用:
- AIDA模型四阶段
- OKR结构中的目标与关键结果差异
- SWOT矩阵中的象限逻辑
2.5 流程型内容:步骤序列+条件分支+角色视角
如:
制定内容策略的五个步骤:
1. 明确目标
2. 受众画像
3. 内容主题池构建
4. 分发渠道匹配
5. 数据反馈优化第三章:让AI更容易“看到你”的页面设计要点
3.1 页面结构深度统一
- 单一URL聚焦一个意图,不混合不同类型问题
- 使用清晰的二级标题(H2/H3)引导模块分区
- 保持页面“答题型思维”风格
3.2 每个页面即“知识单元”
目标是:每个页面都能脱离站点独立理解,像一本百科词条一样被采样。
做法包括:
- 页面开头即定义,结尾有延伸;
- 中段加入“反问结构”或“小节自评”,帮助AI判断逻辑完整;
- 避免无主题文字、堆积资讯杂讯。
第四章:如何构造“AI记得住你”的内容表达模式
以下技巧可让内容在生成模型中留下长效语义痕迹:
4.1 固定表达结构(Framing)
每种类型内容使用一套一致表达:
- 定义类 → “X是……其核心特征包括……”
- 对比类 → “X与Y的五点差异在于……”
- 框架类 → “X模型由三部分组成,分别是……”
重复出现的结构会被模型“编码记忆”。
4.2 嵌套语义标签
在内容中显式指出:
- “本节介绍的是……”
- “以下是……的三种策略”
- “我们将……拆解为以下要素:”
这些提示性句式就是AI“段落分割+主题定位”的锚点。
4.3 可训练格式闭环
尽量让一段内容满足:
- 可用于少样本任务(Few-shot);
- 可直接嵌入提示模板(Prompt Format);
- 拥有句式上的压缩稳定性(易于剪短+改写)。
第五章:提升AI引用概率的五个实战策略(无工具化)
5.1 从“用户中心”切换为“模型中心”内容思维
别再只问“用户怎么读”,而要思考“模型如何理解”。
你提供的不是文章,而是:
- 一组标准语义对;
- 一组可预测逻辑结构;
- 一组低歧义表达组合。
5.2 构建一套可继承表达风格体系
如:
- 所有术语以“是什么+为什么+怎么用”三段结构解释
- 所有列表都配备“编号+强调词+简释”
- 所有模型引用都以“[模型名]由X、Y、Z三部分构成”描述
让你的表达成为“预训练材料里的稳定片段”。
5.3 嵌入知识型锚点句
例如:
- “XX模型是营销领域中引用频率最高的结构之一”;
- “在所有B2B SaaS公司中,90%采用了以下三种策略”;
- “这一方法被广泛应用于X、Y、Z等多个场景”。
这种“领域归属+广泛适配”是AI抽象引用的引信。
5.4 多维视角叙述:术语+使用场景+用户视角
内容不仅有定义,还有:
- 使用对象(谁在用)
- 使用场景(在哪用)
- 语境转换(不同国家/行业叫法)
这类“多源一致性”会让你的内容更容易被当成全局参考。
5.5 生成模型视角的“语义快照”设计
为每段内容配一个可单独理解的“语义快照”段落——结构上自成体系,逻辑上闭环,长度控制在100词内。
即使内容被剪辑、摘要或拆句,仍能保有完整意义,适合AI拼接使用。
第六章:结语——让AI引用你,是一种内容再分配的权力主张
AI不会自动帮你传播,除非你设计了“能被采样、能被压缩、能被组合”的内容格式。
你写的不是一篇文章,而是:
- 一段未来答案的知识母本;
- 一块能被引用的认知积木;
- 一次人工智能生态的参与证明。