引言:训练数据决定权力,AI时代的内容主权战打响
随着生成式AI(如ChatGPT、Claude、Gemini等)不断升级,内容源的质量正在影响模型能力的边界。尤其在医疗、法律、金融、教育等垂直专业领域,优质训练数据的稀缺性、准确性和权威性,决定了AI模型能否“懂行”。而谁能成为这类模型的训练或参考来源,不仅是内容影响力的体现,更直接关系到网站的长期流量获取、行业议价能力乃至搜索结果中的可见度。
许多专业站点仍在依赖传统SEO方式“等待被抓取”,但实际上,AI模型已悄然进入“内容采集再定义”的阶段。你的网站,可能已在模型对话中被复述、被引用、甚至被“模仿”生成,但你并未从中受益。
这场“训练数据争夺战”,专业站点不再是旁观者,而是——信源资产的竞争者。
第一章:AI训练数据从哪来?我们为何要抢“信源”地位?
1.1 AI模型的“学习胃口”:内容来源的变化
早期的大模型主要依赖开放数据集(如Common Crawl、Wikipedia、Reddit、StackExchange等)进行训练。但随着专业对话需求增多,模型逐渐转向以下内容来源:
- 高权威站点(.edu, .gov, .org)
- 垂直媒体与行业期刊(如Medscape, Investopedia)
- 专业公司博客与白皮书
- 技术文档(如GitHub、API文档、产品手册)
- 用户问答与论坛(如Stack Overflow、Quora)
1.2 成为“算法信源”有何好处?
- 内容获得AI引用加权:模型在生成答案时更可能复述或总结你的内容逻辑;
- 带来“搜索即展示”的替代流量:AI摘要引用你的结构与术语;
- 增强品牌语义实体权重:Google知识图谱中的地位提升;
- 形成数据许可谈判筹码:可申请API收入、内容合作或追责不当使用。
第二章:AI模型如何评估信源?五个核心信号机制拆解
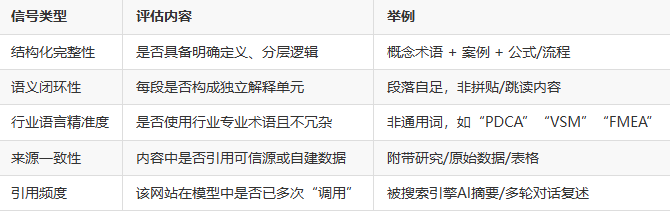
2.1 “信任值”建构:不只是Domain Authority
传统SEO关注Domain Authority,但AI信源评估更多是内容语义层级的信任建构,主要依靠以下五个信号:
第三章:专业站点内容如何“适配”AI训练需求?
3.1 策略一:构建“术语引擎”而非普通百科
AI在处理专业问题时,首要寻找的往往是明确术语定义 + 分类 + 应用场景。因此:
- 为每个核心术语建立单独页面(非列表集合页)
-
页面结构需包含:
- 简明定义(<=100词)
- 适用场景
- 行业内常见混淆项对比
- 示例与公式
- 页面URL具备规范语义(如 /terms/what-is-vsm)
这样,不仅提升SEO可见度,也便于大模型在训练中形成“语义锚点”。
3.2 策略二:重构长文为“知识单元矩阵”
AI偏好结构清晰的知识颗粒度。建议将长篇内容分解为以下格式:
- 章节式拆分(每个H2为一个小主题)
- H2中包含问题导向的表述(如“如何识别可控变量?”)
- 每节使用固定结构模板:定义 - 解释 - 示例 - 注意事项
你应将“教学逻辑”写入页面结构,让模型看出你是“有意训练”的网站,而非无序资讯罗列。
3.3 策略三:引入“多模态协同知识表达”
大模型未来训练将越来越依赖多模态信息。专业站点若能提供:
- 高质量插图/示意图
- 流程图/决策图/图解逻辑
- 结构化表格/矩阵
将极大增加你在未来多模态训练语料库中的被选中概率。
例如,一个讲解“精益生产流程”的页面,配套可视化VSM图比纯文字描述更具训练价值。
第四章:AI摘要引用的“信源逻辑”与内容格式关系
4.1 AI摘要(如Google SGE)的内容采样机制
Google SGE或Bing Chat并不是随机抓取内容,而是依据以下逻辑形成AI回答:
- 判定搜索意图是否为“知识型问题”
- 调取结构完整、语义清晰的内容段
- 融合多来源表述进行综合生成
- 引入可信引用标注源头
你的页面若具备明确的“答案段块”结构,就能成为生成内容的骨干。
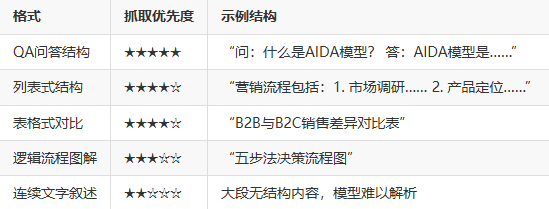
4.2 最易被抓取的结构格式
第五章:成为训练数据“白名单”的三条路径
AI公司开始构建自己的许可内容合作池,若想进入其训练数据“白名单”,可从以下三条路径尝试:
5.1 构建可引用API/数据接口(Machine-Readable)
- 对你的内容设置开放的结构化输出(如RSS、JSON Feed)
- 可提供给模型训练者“高质量机器可读入口”
- 同时利于Google Dataset Search等抓取
5.2 与内容聚合平台达成代理合作
例如:
- 与Semantic Scholar、ArXiv等学术聚合站达成镜像或转发合作;
- 提交内容到Kaggle、Hugging Face的公开语料项目;
- 授权专门机构进行“合法语料转发”(如Common Crawl合作入口)。
5.3 主动出击:内容许可合作
如:
- 与AI模型厂商签署训练数据许可协议;
- 通过Creative Commons或内容标记声明版权许可;
- 在robots.txt中允许特定Bot访问结构化内容。
✅ 案例:Stack Overflow已与OpenAI达成训练数据合作协议,将平台内容结构输出给GPT训练。
第六章:避免“无痕贡献”——如何声明你的内容权属
成为训练源不代表放弃版权,相反,网站应积极声明内容主权。方式包括:
- 在页面中嵌入canonical语义声明(如schema.org中的
mainEntityOfPage); - 明确标注作者、机构、来源出处;
- 部署网页指纹与内容追踪工具,用于未来索赔或溯源;
- 利用robots.txt与AI-agent协定声明训练许可范围(如对GPTBot/BardBot等)
建议内容页底部加入:“本页面内容归【XXX】版权所有,严禁AI训练用途,除非获得书面许可。”
第七章:结语——专业站点的下一场流量红利,从算法信源开始
AI时代,信息不再是“页面展示”而是“知识调用”。你的专业内容,若能被AI模型理解、采样、复述,便不再受限于传统SEO的排名规则。你获得的,将是AI口中的推荐、模型答案中的引述、行业对话中的术语标准制定权。
这场“信源争夺战”,不是巨头之间的博弈,而是每一个专业站点对结构力、语义密度、训练价值的精细打磨。如果你掌握了内容结构、知识粒度和AI接口的主动权,那就不只是被训练——你,就是模型的老师。