我在多个数百万页级别的网站上做过分页优化,从电商目录到资讯归档、从社区帖子列表到产品筛选页。本文把这些年踩过的坑、落地方法与可执行的框架一次性整理出来,目标是帮你在大型站点上用最小的抓取预算,换来最大的信息覆盖,避免重复索引、权重稀释和用户体验倒退。
我将以我的经验讲述:为什么分页会成为问题、搜索引擎现在怎样看分页、可选的技术与策略、我在实战中常用的决策矩阵、以及完整的变更/监测清单。文中穿插表格、示例 URL 设计与操作建议,便于直接落地。
一、为什么分页在大型站点会成为“权重与抓取”的大坑
分页本身是用户体验和数据组织的自然产物:你不可能把 10 万条产品一次性放到一页里。但在搜索引擎面前,分页会产生几个相互叠加的问题:
- 重复索引 / 内容近似:分页系列里相邻页通常包含极大重复(同一集合不同子集),索引系统会为这些近似页面各自做判断,造成重复索引或索引分散。
- 抓取预算浪费:爬虫在站内花大量请求抓取第 N 页而非核心详情页或新内容,尤其在大型站点上,这一点会把“发现新内容”的窗口关掉。
- 权重稀释:内链与外链的传导被分散到分页序列的多页上,没能集中到真正想要提升排名的目标页面。
- 错误指令带来的副作用:比如把分页页面大量
noindex但仍被爬虫抓取,或不当使用 canonical/robots,会让收录与权重路由变得混乱。
这些问题并非抽象猜测——我在做日志分析时,多次遇到 Googlebot 在“第 10 页后”大量停留,关键详情页反而长时间没人抓取的情况,最终通过导航与分页控制把核心页面抓取优先级提升了 3 倍以上,收录速度同步改善。

二、现阶段搜索引擎(尤其是 Google)对分页的态度(要点与引用)
在设计分页策略时,必须先理解搜索引擎如何“看”分页。以下是我在实现策略时把握的几条核心事实(并带出权威来源以便查证):
- Google 现在倾向于把每个分页 URL 当作独立页面来处理;
rel="next"/rel="prev"的影响力长期被弱化,不能再指望它们去“合并”分页权重。([Search Engine Land][1], [Google for Developers][2]) - 给每个分页页面独立且唯一的 URL 是基本要求;不要用片段标识(
#)来替代真实分页 URL。([Google for Developers][2]) - 对于“有大量参数或筛选”导致的近乎无限 URL(faceted navigation),Google 建议通过设计和控制来减少生成的可抓取 URL,否则会造成严重的过度抓取问题。([Google for Developers][3])
- 合理使用
rel="canonical"、sitemap 优化、robots 指令和 noindex,仍然是控制索引路径和权重分配的有效工具,但每种方法都有副作用,要结合站点结构和业务目标权衡使用。([Google for Developers][4])
(上面引用的文档来自 Google Search Central 与行业权威文章,我在落地时会把这些官方建议与项目实际数据结合,避免“教条式”照搬。)
三、分页策略的四种常见处理方式(利弊对比)
在实践里,我把可选策略大致分为四类:全部索引(自洽分页)、首页集中(view-all / 聚合)、noindex 分页、参数/动态页面屏蔽。下面是我的对比表,便于快速决策:
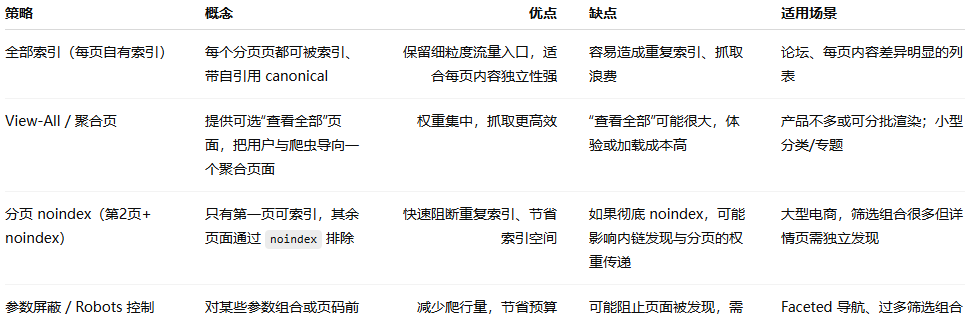
我经常的实战组合是:对高价值的列表(有流量和外链的页)允许索引并自我 canonical;对低价值的深分页或参数页采用 noindex 或 robots 屏蔽,并在 sitemap/内链上保证核心详情页可被发现。这种混合策略在大型站点里最稳妥。
四、设计分页 URL 与 canonical 的规范(我常用的准则)
在我接手的项目里,错误的 URL 设计是很多问题的根源。下面是我强制执行的 URL 与 canonical 规范(可作为编码/开发验收清单):
-
每个分页页面都应有其独立、标准化的 URL,例如:
/category/shoes/ ← page 1 /category/shoes/?page=2 ← page 2 /category/shoes/?page=3 ← page 3或者更优雅的
/category/shoes/page/2/。关键是可被抓取与区分。([Google for Developers][2]) -
不要把第 1 页的 canonical 指向“view-all”或把所有分页 canonical 到第一页(这会混淆索引偏好)。我通常让每页自引用 canonical(
<link rel="canonical" href="...page=2">),除非我们明确要把多个页合并到 view-all。([Google for Developers][2]) -
避免使用 URL 片段(#)来做分页,因为片段通常不会被用作页面区分,容易导致抓取/索引问题。([Google for Developers][2])
-
对参数类 URL 做参数处理策略(如 Google Search Console 的参数处理或服务器端把无意义参数剔除),防止相同内容产生许多参数组合。([Google for Developers][4])
五、面向抓取预算的分页设计 — 我的一套执行流程(落地步骤)
在大型站点,我不会把分页优化当成单次任务,而是把它做成一个周期化流程,分四步走:
步骤 A — 抓取与日志诊断(必做)
- 目标:找到爬虫在哪些分页或参数上浪费最多请求。
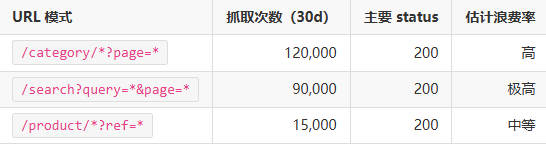
- 我会抓取:服务器日志(至少最近 30 天的 Googlebot)、GSC 抓取统计、站点地图覆盖与抓取成功率。
- 输出:一个“热点浪费清单”,列出 URL 模式(例如
?sort=price、?color=、/page/)以及每个模式的抓取次数与状态码分布。
示例表(抓取热点)
步骤 B — 分类并评估价值(我常用的打分法)
对每类分页做三项评分:发现价值(是否有独立流量/外链)、转化价值(是否带来转化)、技术成本(渲染/服务器负担)。基于得分决定保留索引、noindex 或 robots 策略。
步骤 C — 制定具体控制策略(策略池)
- 高价值分页:保留索引、自引用 canonical,增强内链与 schema(比如 breadcrumb、productList schema)。
- 中价值分页:视情况保留索引但加入规范化内链(“查看全部”引导),限制 index depth。
- 低价值 & 参数组合:用
noindex, follow或 robots Disallow(慎用)、并在站点地图中不包含。([Google for Developers][3])
步骤 D — 推行、监控与回滚
- 上线改动后密切监控:抓取次数分布、收录数量、核心详情页抓取延迟、流量波动。
- 如果出现意外(核心页面被误判 noindex、流量骤降),立即回滚并用日志回溯原因。
- 周期:我通常第 1 周高频监控(每天),第 2-4 周降频(每 2-3 天),之后每月审查一次。
六、常见分页处理策略的技术实现细节与注意点(我在项目中常用的“拆解”)
下面列举我落地时遇到的具体场景与对应解决方案(含注意事项):
场景 1:电商筛选 + 分页(faceted navigation)
问题:筛选 + 排序会生成指数级 URL(颜色 × 尺码 × 排序 × 页码)。
我通常做法:
- 只把“默认排序 + 关键筛选组合(如类目+品牌)”作为可抓取页面;其他组合设置
noindex, follow或禁止抓取。 - 对最常被访问或有流量的筛选组合,放入 sitemap,并确保这些组合有稳定的 canonical。
- 在前端对用户仍然保留完整筛选体验,但在服务器层对 URL 做参数规范化(例如忽略
session_id、utm_*)。
注意:不要直接在 robots.txt 中禁止所有筛选参数,避免阻止详情页的发现。([Google for Developers][3])
场景 2:长列表的分页(如论坛/资讯归档)
问题:第 N 页很少有外链与价值,但爬虫仍然大量抓取。
我通常做法:
- 如果列表每页差异小,考虑提供
view-all(并在该页做分页摘要/分段加载以控制大小),或对第 2 页以后的页面设noindex, follow。 - 确保文章详情页有稳定的内链入口(热门文章、相关内容模块),不能只通过深分页发现。
注意:view-all 页面在数据量过大时可能影响加载,需用分页渲染或动态加载,但仍要保证有常规 URL 供爬虫抓取。([Google for Developers][2])
场景 3:Infinite Scroll(无限滚动)
问题:无限滚动对用户体验友好,但如果没有正确的分页替代,搜索引擎看不到所有内容。
我做法:
- 为无限滚动实现“逐页可访问的 progressive enhancement”——即为每一段内容保留一个对应的 URL(如
?page=2),并在<head>中提供自引用 canonical。 - 同时保证页面在无 JS 情况下仍有分页链接可用(或通过服务端渲染)。
注意:纯客户端加载且没有对应 URL 的 infinite scroll,会让爬虫无法发现深层内容。([Google for Developers][2])
场景 4:rel="prev/next" 的现实用法
问题:很多人仍然依赖 rel="prev/next" 合并分页权重。
我的判断:不要依赖它作为控制权重的核心手段;可以作为“辅助性线索”保留,但主要通过 canonical 与站点地图来引导索引。([Search Engine Land][1], [Google for Developers][2])

七、分页与索引控制:canonical、noindex、robots 的精细用法(决策要点)
这些标签/指令不是互斥的工具,而是需要配合使用的控制器。我在项目里常用的决策逻辑如下:
-
Canonical(首选)
- 作用:告诉搜索引擎“我更倾向于将权重/索引合并到哪个 URL”。
- 我常用场景:当存在轻微重复(如同一列表有少量差别)且希望合并权重时。
- 风险:搜索引擎把 canonical 当作“hint”,可能不 100% 遵循。([Google for Developers][4])
-
Noindex, follow
- 作用:阻止页面被索引,但仍让爬虫跟踪页面上的链接(有利于发现详情页)。
- 我常用场景:深分页、参数组合页面、搜索结果页(site-internal)。
- 风险:若 noindex 被误用在高价值页面,会导致流量损失。([Google for Developers][2])
-
Robots.txt Disallow
- 作用:阻止爬虫抓取特定路径(节省抓取),但同时会阻止搜索引擎读取页面上的内部链接或 meta 指令。
- 我常用场景:静态化的大量日志页、图片仓库目录等。
- 风险:如果你用 robots 禁止一个页面,它的 meta 标签(例如 noindex)就不会被读取,搜索引擎仍可能基于其它线索索引该 URL。谨慎用于会被其他页面引用的路径。([Google for Developers][4])
我常用的实战组合:对“低价值分页”用 noindex, follow;对“参数多、产生大量重复”先在 robots 层面做限制前缀,同时在服务端做参数规范化;对“希望合并权重的系列”用 canonical 指向 view-all(但仅在 view-all 真正代表系列核心且不造成过大页面时)。这种混合策略既保留了链接发现,又能指导索引偏好。
八、监测指标与 KPI(我怎么证明策略有效)
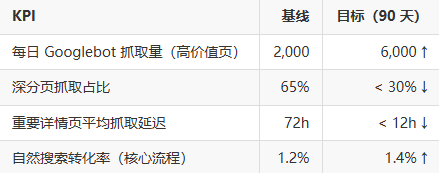
施行分页策略后,必须量化效果。我一般会监测这些关键指标:
- 抓取频次分布(Googlebot 请求 / URL 模式):目标是把抓取集中在高价值 URL。
- 索引覆盖变化(GSC 的覆盖报告 +
site:采样):观察收录页面数量是否合理下降或上升(视策略而定)。 - 核心详情页抓取延迟:重要页面从发现到抓取的平均时间应缩短。
- 自然流量与排名走向:尤其关注那些与分页策略相关的着陆页。
- 服务器响应与渲染时间:在引入 view-all 或 SSR 后,检查服务器负载与 TTFB 是否可接受。
示例 KPI 目标(在实施前可与团队约定):
九、决策矩阵:我如何在复杂场景下快速选策略
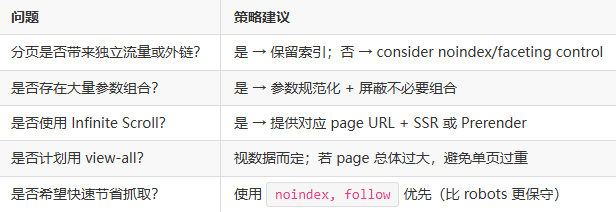
在大型站点里,常常同时面对多个矛盾:用户体验 vs 抓取预算、细粒度流量入口 vs 重复索引风险。以下是我常用的打分矩阵(简化版),用于判断对某类分页采取哪种策略:
评分项(0-3 分):
- 独立价值(是否有独立流量/外链)
- 转化贡献(是否对业务转化有直接贡献)
- 抓取成本(对服务器/渲染的影响)
- 用户体验依赖度(用户是否依赖深分页查找内容)
把每项加总得到 0-12 分:
- 9-12 分(高价值) → 保留索引 + 自引用 canonical + 增强内链
- 5-8 分(中价值) → 视情况保留索引,或设
noindex, follow并在 sitemap 放置精选页 - 0-4 分(低价值) →
noindex, follow或 robots Disallow(配合站点地图和内链确保详情页能被发现)
十、常见误区与我亲眼见到的代价
下面列出一些我在项目中反复见到、且代价高昂的误区:
- 直接把所有 2+ 页放到 robots.txt 禁止:看似迅速省抓取,但会阻止爬虫读取页面上的链接,导致深层详情页无法被发现。
- 把分页全部 canonical 到第一页:会导致分页内容无法独立被索引,且权重流向混乱。
- 依赖 rel=prev/next 合并权重:如前所述,这已不是可靠控制方式。([Search Engine Land][1])
- 忽视 JS 渲染时的可访问性:很多站点因为 SPA 或延迟加载导致分页内容对爬虫不可见而丢失索引。必须做 SSR 或预渲染。([Google for Developers][5])
每当这些误区发生,修复成本往往是数周到数月,而且需要重新建立抓取优先级与信任度。
十一、落地检查清单(上线前必须逐项确认)
在我把分页策略推到生产环境前,会让开发/QA/SEO 三方逐项核对下列清单:
- URL 规范性:分页 URL 可访问、无重复片段(#),并且每页有自引用 canonical(或明确指向 view-all)。
- meta robots:确认哪些页是
noindex, follow,哪些页是 index。 - robots.txt:确认 Disallow 不会阻止重要发现路径。
- Sitemap: sitemap 中仅包含要优先抓取的分页或 view-all。
- JS 渲染:分页在无 JS 下也能被抓取或已做 SSR。
- 内链:详情页是否仍有非分页入口(热门、相关推荐、站内搜索结果)。
- 监控:已布置抓取日志监控、GSC 的索引报告监控与异常告警。
- 回滚方案:出现严重问题时的快速回滚计划(如把 noindex 去掉、恢复旧 canonical)。
十二、我的最终建议与实践心法
在大型站点做分页优化,我的核心心法可以浓缩为三句话:
- 抓取预算是有限的,优先保障核心价值页的发现与抓取。
- 不要把一个策略当作万能钥匙——采用混合策略并持续监控。
- 技术实现要以“可被搜索引擎和不带 JS 的客户端可访问”为底线。
最后补充两点实战性建议:
- 从日志开始:所有决策都基于日志与数据,不要凭感觉改 robots 或大规模 noindex。
- 小步快跑:对大型站点分阶段实验改动(先 1% 流量/部分分类),验证没有副作用后再扩大范围。
附录:快速参考表(便于复制到团队规范文档)
A. 分页决策一页速查表
B. 常用 meta / header 模板(示例)
-
深分页(建议):
<meta name="robots" content="noindex, follow"> <link rel="canonical" href="https://example.com/category/shoes/">(仅在你明确想把权重偏向第一页时使用;慎重)
-
独立分页(建议):
<link rel="canonical" href="https://example.com/category/shoes/?page=2">(自引用 canonical)
结语
大型站点的分页并不是一个单一技术点可以解决的问题,而是“信息架构 + 抓取预算管理 + 索引策略 + 用户体验”四者共同作用的结果。我的经验告诉我:好的分页策略应该是可监控、可回滚、并能以数据驱动逐步优化。按照本文的诊断流程、决策矩阵与实施清单去做,能把抓取浪费降到最低,同时把权重和索引机会集中到真正对业务有价值的页面上。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。