在网站搜索引擎优化(SEO)与技术运维的复杂生态中,重定向是一个不可或缺的工具,常用于网站重构、内容迁移、URL美化或 campaign 跟踪。然而,当重定向未被正确实施时,便会形成一种极具破坏性的结构——重定向链(Redirect Chain)。它犹如一个效率低下、不断损耗的管道系统,看似实现了流量的引导,实则默默吞噬着网站的搜索引擎排名、加载速度乃至用户体验。
我将从专业角度深度剖析重定向链的危害,并提供一套完整、可操作的排查、修复与预防方案,旨在帮助网站管理员、开发者与SEO专家彻底根除此类技术债,保障网站健康运行。
第一章:认识敌人——什么是重定向链?
重定向链是指当用户或搜索引擎爬虫请求一个URL时,需要经过多次跳转才能最终到达目标页面的过程。它通常由一系列连续的301或302重定向构成。
一个典型的重定向链示例:
用户请求
https://old-example.com/page-a(旧服务器)
→ 301 重定向至https://www.old-example.com/page-a(统一www)
→ 302 重定向至https://www.new-example.com/page-a(临时迁移)
→ 301 重定向至https://www.new-example.com/page-a/(添加尾部斜杠)
→ 最终到达目的地https://www.new-example.com/page-a/
在这个例子中,一次请求经历了长达4次跳转才得以满足。每一次跳转都是一个独立的HTTP请求-响应循环,其累积效应将引发一系列问题。
第二章:深层危害——重定向链为何是SEO的“隐形杀手”?
重定向链的危害是多维度、系统性的,远不止是“稍微慢一点”那么简单。
1. 链接权益(Link Juice)的严重损耗
搜索引擎通过链接来传递页面权重(如PageRank)。在301重定向中,理想情况下权重传递接近100%,但并非毫无损耗。当形成链条时,权重会在每一次跳转中经历一次衰减。
- 学术研究与业界共识: 虽然Google官方声称301重定向的权重传递是“近乎完全”的,但Matt Cutts曾提及其中可能存在微小的损耗。在重定向链中,这种微小损耗会被多次放大。假设每次重定向损耗5%的权重,一个包含4次跳转的链条将会导致最终页面只能获得原始页面约 81.5%
(0.95^4 * 100%)的权重。对于依靠大量外链提升排名的核心页面,这意味着一部分宝贵的“投票”被浪费了。
2. 爬取预算(Crawl Budget)的巨额浪费
爬取预算是搜索引擎蜘蛛在特定时间段内愿意并能够抓取你网站页面的最大数量。它是一个有限的资源,对于大型网站尤为重要。
- 机制解析: 搜索引擎蜘蛛在处理重定向链时,必须完整地走完整个链条(发送请求→接收响应→解析新URL→再次请求),才能最终索引到目标内容。一个包含3次重定向的页面,需要消耗蜘蛛4次抓取机会才能处理完毕(3次重定向 + 1次最终页面)。这极大地降低了蜘蛛抓取网站有效内容的效率,导致新页面被发现和索引的速度变慢,重要更新难以被快速捕捉。
3. 页面加载速度的显著下降
每一次重定向都意味着一次完整的HTTP请求-响应往返(Round Trip)。每次往返都伴随着DNS查询、TCP连接、TLS握手(HTTPS)、请求发送、响应等待等网络延迟。
- 用户体验影响: 尤其是在移动网络或高延迟环境下,每一次额外的跳转都可能增加数百毫秒的延迟。这直接违背了Core Web Vitals(核心Web指标)中对加载性能(LCP)和交互性(FID/INP)的要求。加载速度变慢会导致用户跳出率升高,转化率下降,并间接影响搜索排名。
4. 链接与跟踪数据的失真
在数字营销分析中,重定向链会扰乱数据统计的准确性。
- 流量来源归属: 最终到达目标页面的用户,其原始来源(如Google自然搜索、社交媒体链接)可能会在多次跳转中被剥离或错误归属,导致 analytics 报告失真。
- UTM参数丢失: 如果重定向配置不当,UTM等跟踪参数可能在跳转过程中丢失,使得无法准确分析营销活动的效果。
5. 潜在的索引与排名问题
在极端情况下,过长或过于复杂的重定向链可能会让搜索引擎蜘蛛感到困惑,甚至无法正确索引最终目标页面。虽然现代爬虫处理重定向的能力很强,但这无疑增加了不必要的风险。同时,由于权重损耗和速度延迟,目标页面的排名潜力会受到直接或间接的负面影响。
第三章:实战排查——如何系统性地发现重定向链?
要解决问题,首先必须发现它们。以下是专业SEO人员使用的排查方法。
1. 使用浏览器开发者工具(手动检查)
这是最快捷的初步检查方式。
- 步骤:
- 打开Chrome或Firefox的“开发者工具”(F12)。
- 切换到“Network”(网络)标签页。
- 勾选“Preserve log”(保留日志)。
- 在地址栏输入你想要检查的URL并回车。
- 观察“Network”面板中的请求列表。任何状态码为 301 或 302 的请求都是重定向链中的一环。最终状态码为 200 的请求才是目的地。
- 优点: 快速、直观。
- 缺点: 难以大规模批量检查。
2. 使用SEO爬虫工具(批量审计)
这是最全面、最专业的方法。推荐使用 Screaming Frog SEO Spider, Sitebulb, DeepCrawl等。
- 步骤:
- 在爬虫工具中配置爬取时“跟随重定向”。
- 输入网站域名,开始爬取。
- 爬取完成后,使用内置的过滤器或报告功能找出重定向链。
- 关键报告与筛选:
- 筛选
Status Code为3xx:查看所有发生了重定向的URL。 - 查看“Redirect Chains”报告:高级工具(如Screaming Frog)会直接列出所有检测到的链条。
- 注意“Hop”列:显示跳转次数。大于1的就需要关注。
- 导出列表:包含起始URL、每一步跳转的URL、最终目的地、跳转次数。
- 筛选
表:Screaming Frog爬虫结果示例表
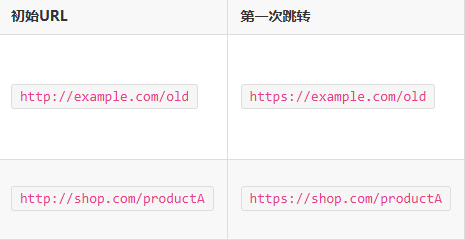
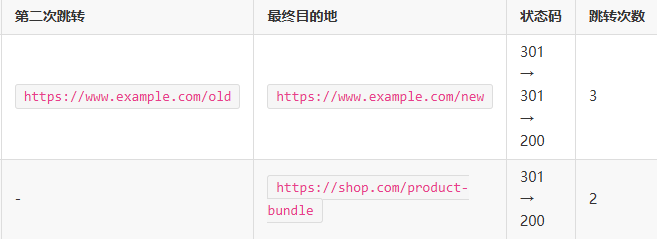
3. 使用命令行工具(CURL)
对于技术人员,curl 命令是强大的诊断工具。
- 命令:
curl -I -L -w "Redirects: %{num_redirects}\nFinal URL: %{url_effective}\n" https://your-url.com-I: 只获取头部信息。-L: 跟随重定向。-w: 写入输出信息,这里显示总重定向次数和最终URL。
- 输出解析: 命令会输出每个跳转的HTTP头,最后显示总跳转次数和最终URL,一目了然。
第四章:根除问题——如何修复现有的重定向链?
发现重定向链后,修复的核心原则是:将多跳重定向压缩为直接从原始URL到最终目标URL的单跳重定向。
修复流程:
- 审计与清单化: 使用第三章的方法,导出网站上所有存在的重定向链,形成一个待修复列表。
- 分析链条成因: 理解每个链条是如何形成的(e.g., http->https, non-www->www, 旧结构->新结构)。
- 修改服务器配置: 这是最根本的解决方法。直接编辑服务器的配置文件(Apache的
.htaccess文件或Nginx的.conf文件),将旧URL直接重定向到最终的新URL。- 修复前(链式):
# 在.htaccess中,可能分散着多条规则 RewriteRule ^old-page.html$ /new-page.html [R=301,L] RewriteRule ^new-page.html$ /final-page.html [R=301,L] - 修复后(直接):
# 修改为一条规则,直接指向最终目标 RewriteRule ^old-page.html$ /final-page.html [R=301,L]
- 修复前(链式):
- 测试验证: 修改配置后,务必使用curl或浏览器开发者工具再次测试原始URL,确认其现在仅返回一次
301重定向就直接到达了最终页面。 - 监控与更新: 修复后,监控Google Search Console中的“覆盖率”报告,确保没有因修复而产生新的404错误。同时,如果有能力,应使用工具(如Ahrefs, Semrush)监控外链,并尝试请求重要外链的拥有者将链接更新为最新的直接URL。
第五章:防患未然——如何从源头预防重定向链?
预防远胜于治疗。建立良好的开发与运维规范是杜绝重定向链的关键。
1. 建立规范的重定向流程
- 任何需要设置重定向的变更(如页面下线、内容迁移)都必须通过工单系统提出申请。
- 申请中必须明确原始URL和唯一的目标URL。实施人员在操作前,必须核查该目标URL本身是否又是一个重定向(即是否是链中的一环),确保其是最终目的地。
2. 在开发与预发布环境中进行测试
- 重定向规则应在开发(Development)或预发布(Staging)环境中充分测试,然后再部署到生产环境。使用爬虫工具爬取预发布环境,可以有效提前发现潜在的链条问题。
3. 实施统一的URL标准
- 在网站规划初期就确定唯一的URL标准(例如,始终使用
https://www.example.com/或始终使用https://example.com/),并通过一条重定向规则强制执行它,避免后续修补。
4. 定期进行SEO技术审计
- 将“重定向链审计”作为每季度或每半年例行SEO技术健康检查的必选项。使用爬虫工具自动化这一过程,便于及时发现问题并修复。
5. 谨慎使用CMS插件与代码级重定向
- 许多WordPress重定向插件容易在不知情的情况下创建出重定向链。优先选择在服务器端配置重定向(如.htaccess),这不仅是性能最佳实践,也更能保证你对重定向逻辑的完全控制。避免使用JavaScript或Meta Refresh进行重定向。
总结:重定向链处理清单
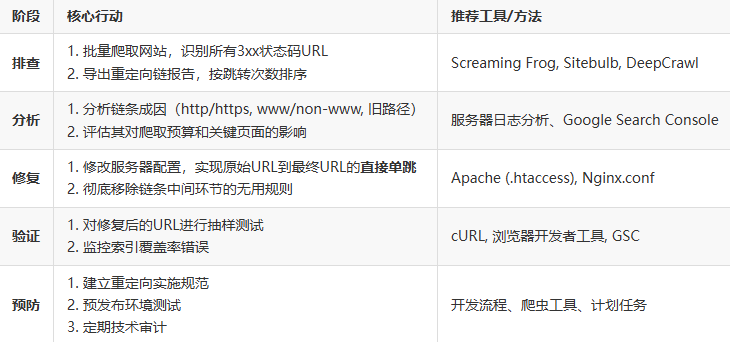
结论:
重定向链绝非无伤大雅的技术细节,而是侵蚀网站健康、阻碍其发挥全部潜能的系统性风险。通过本手册提供的系统性方法,技术团队和SEO从业者可以有效地将其排查、修复并最终预防。治理重定向链是一项投入产出比极高的技术SEO工作,它能立即为网站释放出被禁锢的爬取预算、链接权益和加载速度,为稳定和提升搜索引擎排名打下坚实的技术基础。