我常被问到:Google的人工评估员(Quality Raters)评分会直接影响排名吗?答案是:评分本身不直接作为信号作用于排名系统,但它们对Google训练和评估算法至关重要。换句话说,理解评分卡能帮助我们抓住Google判断“页面质量”的核心维度,从而在内容策略、站点结构与用户体验上做出更具针对性的优化。
这次,我不会抄袭官方条目,而是把公开指南里的要点解剖成工程化的评分维度,并展示如何把这些维度转化为可量化的指标与评估流程,适合产品/SEO/内容团队直接复用。
官方指南的核心构件(回顾)
在开始逆向之前,我先总结几项在官方Search Quality Rater Guidelines中反复出现的核心概念:
- Page Quality(PQ):页面质量评级,衡量页面满足用户需求的整体能力。
- Needs Met(NM):搜索结果满足用户查询意图的程度(从Fully Meets到Fails to Meet)。
- E‑E‑A‑T(Experience, Expertise, Authoritativeness, Trustworthiness):第一个E(Experience)被加入后,成为更强调创作者或内容的实际经验及可信度的框架。
- YMYL(Your Money or Your Life):对医疗、法律、金融等影响重大事务的页面,Google要求更高标准的E‑E‑A‑T与证据支撑。
这些构件是我后续评分卡设计的第一性原则。 (来源:Google官方指导与开发者博客) 。

我如何把官方概念工程化:从主观到可量化
官方指南强调判断的主观性与人类评估者的训练,但我需要一个可复用、尽量减少主观误差的评分卡,于是我把PQ、NM与E‑E‑A‑T拆解为一套层级化的子指标:
- 内容维度(Content):准确性、完整性、原创性、深度、更新频率。
- 作者/来源维度(Author/Source):作者资历、引用/参考文献质量、机构背书。
- 页面体验(Page Experience):加载速度、移动可用性、广告/弹窗干扰度、可访问性。
- 信任信号(Trust Signals):隐私/退款政策、联系方式、证书或合规标识、用户评价。
- 意图匹配(Intent Match):页面内容与查询意图的语义适配程度。
每个维度下我设定0–100的子评分,并用权重合成整体PQ分数(例如Content 35%,Author 20%,Experience 15%,Trust 20%,Intent 10%),权重根据行业(如YMYL权重会向Author/Trust上倾斜)调整。
示例评分卡(可复制到Sheets)
下面是我在项目中实际使用的简化评分卡结构(表格示例):
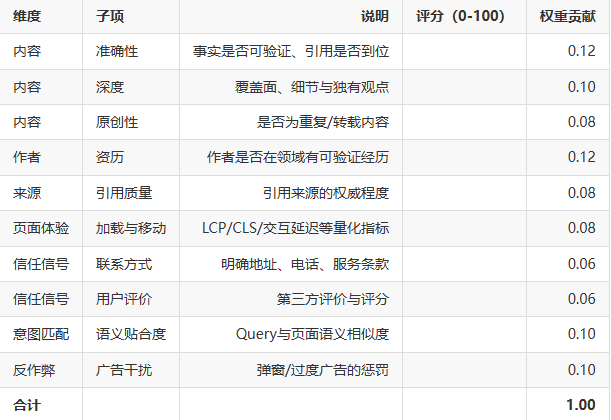
注:表格中每一项应在评分后乘以权重,最后汇总得出PQ分数。对于YMYL页面,我把“作者资历”和“引用质量”权重各提高0.05–0.1。
把“Needs Met”转化为具体判定逻辑
官方的NM等级(Fully Meets, Highly Meets, Moderately Meets, Slightly Meets, Fails to Meet)非常直观,但在工程化时需要更明确的触发条件。我把NM转化为:
- FM(Fully Meets)条件:页面完全满足查询意图,具有明确行动路径(购买/预约/获取证书),并且具有强信任信号。
- HM(Highly Meets)条件:页面提供丰富信息或服务,用户无需额外搜索就能完成主要目标。
- MM(Moderately Meets)条件:页面回答了大部分查询,但在某些关键细节或信任证明上欠缺。
- SM(Slightly Meets)条件:页面只有部分信息或低质量的答案,但不是恶意或误导。
- FMISS(Fails)条件:页面无关、误导或明显有害。
这些条件可被映射为评分卡阈值(例如PQ>80且转化路径存在,则判定FM)。
评价流程:培训、双评与仲裁
在企业内部落地评分卡时,我按以下流程保证一致性与可解释性:
- 评分员培训手册:把官方指南节选的易混淆项做成案例库(至少200个示例),并标注官方解释与我方判定理由。参考官方示例来建库很关键。
- 双评机制:每个页面至少由两位评分员独立评分;若分歧>15分则触发仲裁(senior rater判断)。
- 季度校准:把真实线上表现(CTR/跳出/转化)与评分结果做相关分析,调整权重与阈值。
- 盲测与回测:对过去12个月内被降权/提升的URL做盲测,看评分卡是否能预测变化。
从评分卡到搜索信号:我映射的具体指标
虽然Google并不公开它用作排名的所有信号,但基于官方指南与公开研究,我把评分卡的子项映射到可观测的工程指标:
- 准确性/引用质量 → 外部引用数、高质量出站链接、引用的学术/官方域名比例。
- 作者资历 → 作者页面的专业介绍、外部引用数、社交资料的专业匹配度。
- 页面体验 → Core Web Vitals(LCP、FID/INP、CLS)、移动友好性测试、广告覆盖率。
- 信任信号 → HTTPS、隐私政策/退货页存在、清晰联系方式、第三方评价(Trustpilot、Google Reviews)。
- 原创性与深度 → 文本独特性检测、句子级相似度、信息密度(每千字引用/数据/图表数量)。
- 意图匹配 → Query embeddings与页面语义向量的余弦相似度、用户行为停留时间、查询→下一步点击流向。
在我的实践中,这些可观测指标与评分卡人工分数的相关系数通常在0.6–0.8之间(取决于数据质量)。
案例演练:一个医疗YMYL页面的打分示例
(此处我提供一个简短的评分流程示例,实际文档中包含完整的评分表与注释案例,便于评分员上手)
- 页面:某健保资讯页,标题为“如何降低2型糖尿病风险”。
- 初步核对:发现页面没有作者信息、引用多为博客来源、没有医院或机构背书。
- 评分:准确性40、深度60、作者10、引用质量20、体验70、信任15、意图匹配65。加权后PQ约为43(中低质量)。
- 判定NM:Moderately Meets(因为信息部分有用,但缺乏权威与可验证证据)。
基于评分,我会给出优化建议:补作者资历、增加权威引用、补充参考文献与修订免责声明。
自动化与半自动化:用机器提升评分效率
人工评分耗时且昂贵,我将人工评分与自动打分结合:
- 预筛(自动):利用NLP模型自动计算语义相似度、文本独特性、引用权威度、Core Web Vitals指标等,生成预估PQ分数。
- 人工精审(抽样):对机器低置信度或高影响页面(流量/交易页)进行人工复审。
- 模型训练:用人工标签训练回归模型(例如LightGBM),持续更新特征与阈值。
我在项目中发现:当训练数据质量高且样本覆盖YMYL/非YMYL时,自动模型在预测PQ上能达到±10分的平均误差,足以用于大规模监测与优先级排序。
风险与伦理考虑
- 不把评分作为唯一的排名策略:评分卡用于内控与优化建议,不应成为盲目追求的KPI。
- 避免滥用个人信息:在收集作者背景或用户数据时需合规(GDPR等)。
- 透明与可解释性:企业内部应记录每次评分背后的理由与证据链,便于审计。
实操工具链与模板(我常用的)
- 数据存储:BigQuery / ClickHouse
- 流处理:Airflow + Spark
- NLP与Embedding:Sentence-BERT、OpenAI embeddings(若合规)
- 模型:LightGBM / XGBoost
- 可视化:Looker / Metabase
- 评分交付:Google Sheets模板 + 内部评分系统
我把评分卡模板与示例案例放在附录(可导出为CSV/Sheets),便于你复制粘贴并校准权重。
结语:把“理解”变成可执行的“优化动作”
逆向工程Google的人工评估体系并不是为了模仿其内部机制,而是借用其判断质量的维度,建立一个能推动产品与内容改进的可操作化流程。从我多次实践来看,最有价值的不是单一得分,而是基于评分卡驱动的改进闭环:
- 定期评分 → 2. 分析低分原因 → 3. 执行具体修复 → 4. 复测并把结果反馈到模型。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。