过去几年里,我在多个项目中投入大量时间去理解“行为数据是否影响排名”这个问题。实践中我见过令人困惑的结果:同一类页面在不同阶段、不同流量来源下表现出完全相反的行为模式,却被团队用同一个“好/坏”阈值评判。为避免反复踩坑,我把这些经验总结为本文,希望把“直觉式的优化”转换成“因果导向的实践”。
我会阐明常见的悖论(并给出可复现的判别方法)、分享我用来验证因果关系的实验设计、提供工程化的信号处理建议以及一份面向运营的故障排查清单。
我们在说什么:定义与基本概念
在讨论之前,我先把核心概念明确化:
- 行为数据(Behavioral Signals):包括但不限于点击率(CTR)、停留时长(Dwell Time)、跳回/翻出(Pogo-sticking)、页面浏览深度、会话转化等由用户行为产生的可量化事件。
- 用户体验信号悖论(UE Signals Paradox):指相同或相似的行为指标在不同环境或不同解读下可能代表相反含义(即既可能是“页面好”的证据,也可能是“页面差”的证据)。
- 因果 vs 相关(Causation vs Correlation):行为数据与排名之间通常呈现相关,但因果关系需要通过干预与实验来验证。
对我而言,核心问题不是“这些信号有没有用”,而是“在什么条件下它们是有用且可靠的”。

常见用户体验信号及其直觉含义(我如何看)
下面是我经常用来判断页面质量的几个行为信号,以及我对它们直觉性的说明:
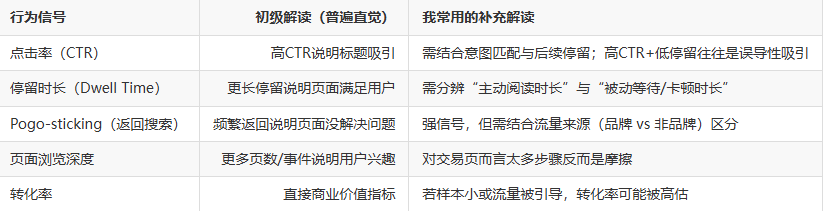
上述对照表是我在分析时的第一道过滤:若某项信号与直觉相悖,我会立刻去找可能的混淆因素。
典型悖论与判别方法(我如何诊断)
1)高CTR但高Pogo-sticking:吸引力与兑现力不匹配
现象描述:页面通过噱头式标题拿到大量点击,但在秒级或短时内用户返回搜索结果。
我如何判别:
- 测量“进入后30s内返回”的比例;
- 观察从搜索来的流量与从社媒/品牌流量的差异;
- 把页面按查询意图(信息/导航/交易)分组,查看该模式是否在同一类型页面普遍存在。
常见原因:标题承诺与页面内容不符、加载失败或关键内容被广告/弹窗遮挡、移动端体验差。
应对策略:修正snippet、改善首屏内容的承诺兑现、优化前端加载与广告策略。
2)长停留并不总是好事:困惑与质量的混淆
现象描述:页面停留时间很长,但并没有带来更高的转化或更低的跳出率。
我如何判别:
- 使用主动交互事件(如滚动深度、阅读事件)与浏览器可视区域检测区分“主动阅读”与“空闲等待”;
- 检查前端性能(LCP/INP)与页面错误日志,排除加载或渲染问题;
- 结合热图(如点击热图)判断用户停留时在做什么。
常见原因:用户被复杂表单卡住、页面结构导致阅读困难、个别内容过于学术化且不实用。
应对策略:简化页面流程、增加小结/要点、提供显眼的CTA(交易页)或更多分层信息(信息页)。
3)低行为指标但高转化:短页胜出
现象描述:某些落地页虽停留短、页面深度低,但转化率高。
我如何判别:
- 把页面分类为“交易页/落地页”并调整期望值;
- 观察转化所需的关键路径(是否只需一次点击或一次电话);
- 检查是否存在外部激励(优惠券、付费推荐)导致转化异常。
结论:行为指标要与页面目标对齐,不能把同一套阈值套用于所有页面。
4)流量来源改变导致行为信号虚化
现象描述:当页面从社媒或付费渠道获得大量流量,行为信号(停留/深度)与搜索来源相比显著不同。
我如何判别:
- 把行为指标按流量来源拆分;
- 使用归因模型判断不同渠道的用户差异。
结论:在把行为数据作为排名或质量证据之前,一定要先做流量分层。
因果推断:我常用的三种验证方法
单看关联容易误导。为了区分因果,我在实践中常用以下方法:
A)随机化实验(A/B测试)——最稳健的因果证据
我会在有足够搜索流量的页面上做Snippet/Title/首屏内容的随机化测试:
- 随机分配搜索展示(或在站内做流量分流);
- 仅修改可能影响行为的元素;
- 观察一段时间内行为指标与排名是否出现可重复的变化。
我强调长期观察(至少4–8周),以排除短期噪声。
B)中断时间序列分析(Interrupted Time Series)
当无法随机化时,我用断点分析:在一次可控变更前后建模,加入外部控制变量(总体搜索趋势、季节性),观察是否存在显著的结构性变化。
C)倾向评分匹配与工具变量(当观测数据被迫时)
在纯观察数据情形下,我会用倾向评分匹配(Propensity Score Matching)把处理组与控制组在可观测特征上匹配,或者寻找工具变量来剔除潜在的内生性。
在多个项目里,这三种方法结合使用能把“行为-排名关系”从猜测变成可证伪的假设检验。
在排序模型中如何合理使用行为信号(我的工程化方案)
若要把行为信号纳入排序或监测体系,我一般遵循以下工程原则:
- 分层建模:对信息类、交易类与导航类页面分别训练行为到质量的映射函数。
- 信号加权与可信度估计:加入样本大小与波动度的置信度调整,小样本行为信号权重衰减。
- 时间窗口与延迟机制:行为数据使用多窗口平滑(如7/30/90天)并对短期异常做截断。
- 多信号融合:行为信号作为某些监督学习目标的标签之一,但必须与内容质量、链接、结构化数据等信号共同作用。
- 异常检测与自动回退:若某个页面或流量来源的行为信号出现异常(疑似操纵或异常流量),自动降低其影响并触发人工复核。
这些设计可以显著降低被操控或被误判的风险,同时保留行为信号提供的实时反馈价值。
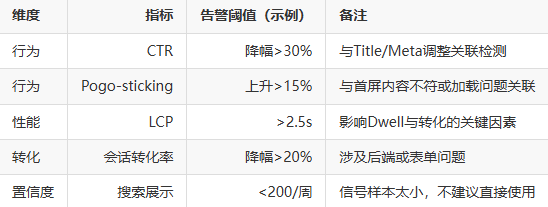
工程实现细节:我常用的数据与指标集合
以下是我在实践中会采集与计算的一组指标(供数据工程团队参考):
基础指标:展示、点击、CTR、会话数、独立访客(UV)、页面浏览量(PV)。
行为衍生指标:
- Dwell median/percentiles(按流量来源分),
- Pogo-sticking rate(进入后30s内回退),
- Scroll depth 50%/75%比率,
- Event-based active time(浏览器可视区内的用户主动事件时长),
- 转化漏斗步骤完成率(按渠道分)。
性能与质量指标(用于解释):LCP、INP、CLS、前端错误率、第三方脚本延迟。
置信度评估:样本量(搜索展示计数)、行为指标的标准差、流量来源分布。
下面是一张简化的监控表格样例,便于产品/运营快速定位问题:
抗游戏化策略(我如何保护数据不被操控)
行为信号易被人为干预,我在设计系统时引入以下防护:
- 来源信任等级:对付费、社媒、内部推广等流量赋予不同信任权重或屏蔽;
- IP/UA风控规则:对短期内产生大量行为但无历史的来源做阈值限制;
- 多模态验证:行为提升必须能在至少一种“坚实信号”上得到印证(例如后端转化或外部引用提升);
- 置信区间与保守更新:模型更新时把行为信号的影响限制在置信区间内,避免短期波动造成排名剧烈波动。
这些实践在我负责的产品中有效减少了恶意干预带来的噪声。
案例回顾:我在两个项目中的实证观察(简述)
案例一:知识型内容站点——修正高CTR但高Pogo问题
问题:一系列标题改版后CTR提升,但进入后30s回退率飙升。
我做的事:回滚标题改动、对首屏增加“快速结论”段落、并逐页监测Pogo率。
结果:在两周内,CTR回归稳定且Pogo-sticking下降30%,页面排名在次月稳定提升。
案例二:电商落地页——短页高转化的正确评估
问题:某类落地页停留短、跳出率高,但转化稳定并贡献营收。团队误判为页面差。
我做的事:把页面归类为交易页,调整行为阈值,并监测转化漏斗深度与复购率。
结果:页面继续保留短页设计,同时在搜索摘要中强调购买路径,排名与转化双赢。
给产品与SEO团队的行动清单(我亲测有效)
- 页面分层:先把页面按目标(信息/交易/导航)分类,建立不同的行为阈值。
- 分渠道监控:行为信号必须按流量来源拆分并设置信任等级。
- 做A/B:对高流量页面进行随机化实验,而不是仅靠关联性判断。
- 采集可解释事件:增加主动交互事件(阅读标记、滚动、表单交互)以分辨主动停留。
- 对异常流量自动降权:实现IP/UA风控规则,防止被游戏化。
- 把行为信号作为反馈,不是唯一目标:用它们来优先级排序与快速迭代,而非直接作为排名的“单一真理”。
总结:把行为数据变成可行动的证据
在我多次实践中,行为信号既是非常宝贵的实时反馈,也是一把容易伤到自己的双刃剑。它们能帮助我们发现用户痛点、验证改版效果、并在短期内提升转化;但若不做分层、去混淆与做因果验证,就会导致误判和被操控。
我的工作原则很直接:定义明确的目标 → 分层采集与分渠道分析 → 优先用干预实验验证因果 → 工程化防护与置信度控制 → 把行为数据当作改进的反馈环。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。