作为一名长期从事SEO优化的专业人士,我深知搜索引擎收录机制的复杂性和精细度。理解搜索引擎如何从海量网页中挑选、抓取、分析,再最终收录到索引库,是提升网站排名和流量的基础。本文将从专业视角,全面解读搜索引擎收录机制,从最初的爬取(Crawling)到最终的索引(Indexing),每一步的原理与实操关键,帮你理清整个过程的核心要点,避免收录瓶颈,提升网站整体表现。
一、搜索引擎收录机制概述
搜索引擎收录机制主要包含三个阶段:爬取(Crawling)、解析与处理(Parsing and Processing)、索引(Indexing)。这三步相辅相成,共同完成网页的发现、理解与存储。

二、第一步:爬取(Crawling)详解
爬取是搜索引擎收录机制的入口,爬虫通过不断访问网页,发现新页面和更新内容。
1. 爬虫工作原理
爬虫起点是已知的URL集合,包括历史抓取URL和网站地图。它通过分析网页中的超链接,不断扩大抓取范围。爬虫遵循robots.txt规则、meta标签指令(如noindex、nofollow)来判断哪些页面允许抓取。
2. 爬取频率与爬取预算
搜索引擎为每个网站设定爬取预算(Crawl Budget),受服务器性能、网站权重、内容更新频率等影响。优化网站结构和提升服务器响应速度,可以提高爬取频率。
3. 动态内容与JavaScript抓取
现代网站大量采用JavaScript动态加载内容,爬虫需进行渲染才能获取完整内容。谷歌等搜索引擎采用两阶段渲染机制,先抓取原始HTML,再执行JavaScript,确保动态内容被发现。
三、第二步:解析与处理(Parsing and Processing)
网页被抓取后,搜索引擎对内容进行深度解析,提取有用信息并分析页面结构。
1. HTML和DOM解析
搜索引擎解析HTML代码,构建DOM树,理解页面的文本、图片、链接等元素。语义化标签如<article>, <header>帮助搜索引擎准确理解内容结构。
2. 内容理解与语义分析
通过自然语言处理技术,搜索引擎分析文本语义,识别关键词、主题和用户意图,判断内容是否有价值,避免重复和垃圾内容。
3. 处理动态和富媒体内容
动态加载的内容经过渲染后被解析,视频、图片等富媒体通过alt标签、标题等辅助信息被理解,提升内容丰富度的评价。
四、第三步:索引(Indexing)
索引阶段是将解析后的信息存储到搜索引擎的数据库,便于快速检索。
1. 索引结构和倒排索引
搜索引擎采用倒排索引结构,将关键词映射到包含该词的网页列表,优化检索效率。
2. 内容权重与排名信号
索引不仅存储内容,还计算页面权重、关键词相关性、用户体验等排名信号,作为后续排序的依据。
3. 移除与更新机制
对于质量下降或不再存在的页面,搜索引擎会定期更新索引,删除过时信息,保证结果的准确性。
五、优化建议:顺畅收录的关键实践
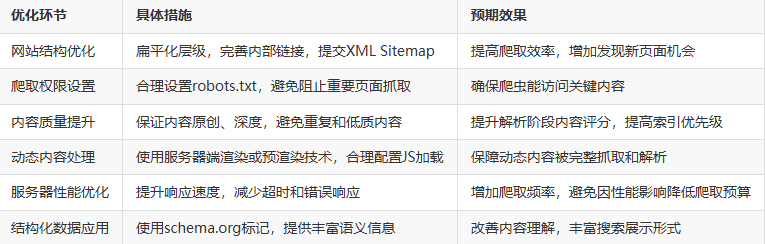
六、常见误区与排查技巧
-
误区一:大量提交无用页面的Sitemap
会浪费爬取预算,建议筛选高价值页面提交。 -
误区二:robots.txt误封爬虫
检查robots.txt配置,避免误阻重要资源。 -
误区三:忽视动态内容抓取
确保JS内容可被渲染,使用Search Console抓取测试工具。 -
误区四:内容重复过多
运用canonical标签,清理重复内容。
七、结语
理解搜索引擎收录机制,从爬取到解析再到索引的每一步,都需要我们精细把控。只有把握好爬虫行为规律、优化内容和结构、提升技术支持,才能让网站顺利被搜索引擎收录,获取更稳定和持续的流量增长。作为一名SEO从业者,我深信深入洞察这一机制,是制定高效优化策略的前提。希望这篇全面解读,能帮助你精准定位收录瓶颈,实现网站的持续优化突破。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。