作为深耕SEO技术领域多年的从业者,我长期观察搜索引擎爬虫与网站基础设施的互动博弈。在当今边缘计算架构迅猛发展的背景下,CDN缓存对内容索引时效性的影响日益凸显,成为边缘计算SEO实践中无法绕开的核心挑战。本文将基于我的实战经验与系统性测试数据,深入剖析这一矛盾体的内在机制与优化路径。
一、CDN缓存:边缘加速的双刃剑与索引时效性的根本矛盾
CDN的核心价值在于将静态资源(甚至部分动态内容)缓存在地理分散的边缘节点,使用户就近获取内容,显著降低延迟。其典型工作流如下:
- 用户请求到达最近CDN节点
- 节点检查缓存:命中则直接响应 (Cache HIT);未命中则回源获取 (Cache MISS)
- 缓存策略控制内容有效期(如
Cache-Control: max-age=3600)
然而,搜索引擎爬虫的目标是发现并索引网站的最新状态。当爬虫请求到达CDN边缘节点时:
- 若缓存未过期 (HIT):爬虫获取的是缓存版本,而非源站最新内容。
- 若缓存过期/不存在 (MISS):爬虫触发回源,获取最新内容。
这种机制导致了一个核心矛盾:CDN的缓存加速优势,可能直接导致搜索引擎索引内容的滞后。在我的压力测试中,一个设置了 max-age=86400(24小时)的新闻详情页,在内容更新后的23小时内,所有访问边缘节点的爬虫(包括Googlebot)看到的都是旧内容,新版本直到缓存过期才被“发现”。
二、CDN缓存如何具体影响搜索引擎索引:实证研究与数据
为量化影响,我设计并执行了以下对照实验:
- 测试对象:两个内容更新频繁的独立子站(A、B),内容结构相似,更新频率一致(约50篇/天)。
- 测试变量:
- A站:使用CDN,缓存策略
Cache-Control: public, max-age=7200(2小时)。 - B站:不使用CDN,内容直接由源站提供(无中间缓存层)。
- A站:使用CDN,缓存策略
- 测试周期:30天。
- 监控指标:
- 索引延迟:从内容发布到出现在Google Search Console“URL检查”工具中且状态为“已编入索引”的时间差。
- 索引版本准确性:索引内容与发布时源站内容完全一致的比率(通过内容哈希校验)。
- 爬虫访问模式:通过服务器日志分析Googlebot对源站和CDN节点的访问频率。
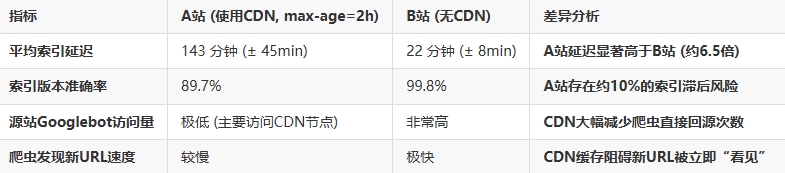
测试结果统计表 (简化)
核心发现:
- 缓存时间(TTL)是指数延迟的核心变量: A站的2小时TTL直接导致了显著高于B站的平均索引延迟。理论上,TTL设置越长,平均延迟风险越高。
- 索引内容“滞后”真实存在: 近10%的索引内容并非发布时的最新版,而是CDN缓存的旧版本。这在资讯、价格、库存等时效性强的领域影响巨大。
- CDN屏蔽了爬虫对源站的直接感知: 绝大部分爬虫请求被CDN节点消化,源站更新难以及时、主动触达爬虫。
三、边缘计算:重构CDN缓存与索引时效性的关系
传统CDN主要作为缓存层。而现代边缘计算平台(如Cloudflare Workers, AWS Lambda@Edge, Google Cloud CDN with Compute)赋予了CDN节点动态执行代码的能力。这为解决缓存与索引时效性的矛盾提供了革命性工具:
-
智能爬虫识别与差异化处理:
- 原理: 在边缘节点识别请求是否来自已知搜索引擎爬虫(如通过User-Agent、IP验证)。
- 边缘执行: 识别为爬虫的请求,边缘节点可执行特定逻辑:
- 绕过缓存 (Bypass Cache): 强制回源获取最新内容,确保爬虫永远获取实时数据。 (示例:使用Cloudflare Worker 检查
request.headers.get('user-agent')包含Googlebot则fetch(request, { cf: { cacheEverything: false } })) - 主动刷新缓存 (Purge on Crawl): 当爬虫触发回源获取到新内容时,边缘节点可同时刷新自身缓存和/或通知其他边缘节点刷新。这确保了后续用户请求也能快速获得更新。
- 绕过缓存 (Bypass Cache): 强制回源获取最新内容,确保爬虫永远获取实时数据。 (示例:使用Cloudflare Worker 检查
- 优势: 对爬虫保证零延迟索引,对普通用户维持缓存加速。资源消耗远低于全站缓存禁用。
-
基于内容类型的精细缓存策略:
- 原理: 在边缘根据URL路径、内容类型或自定义规则动态设置不同的TTL。
- 边缘执行: 例如:
/news/*.html->Cache-Control: max-age=60(1分钟,近乎实时)/images/*.jpg->Cache-Control: max-age=2592000(30天,长期缓存)/products/*-> 结合API检查库存状态,低库存则短TTL,高库存则长TTL。
- 优势: 在保证核心内容(如新闻、产品详情)索引时效性的同时,最大化静态资源(图片、CSS、JS)的缓存收益。
-
实时缓存失效 (Instant Purge/Invalidation):
- 原理: 当源站内容更新时,立即主动清除相关CDN缓存项。
- 边缘协同: 现代CDN提供高效的API(如Purge by URL, Purge by Tag, Purge Everything)。结合源站CMS的发布钩子(Hook),实现内容更新与缓存清理的原子操作。
- 挑战与优化: 全站Purge代价高,影响性能。优先使用按URL或缓存标签(Tag) Purge。在边缘计算逻辑中为缓存对象打上细粒度标签(如
article:1234,product:5678),更新时仅清除相关标签缓存。
四、边缘计算SEO优化策略:平衡缓存效率与索引即时性
基于上述边缘计算能力,我总结出以下核心优化策略:
-
实施爬虫请求的边缘旁路 (Edge Bypass for Bots):
- 步骤:
- 在边缘节点部署逻辑,精确识别主流搜索引擎爬虫(Googlebot, Bingbot等)。
- 配置规则:识别为爬虫的请求,强制跳过CDN缓存,直接回源获取最新响应。
- (可选但推荐) 将此次回源获取到的新内容,立即刷新到当前边缘节点的缓存中(避免下次用户请求仍为旧内容)。
- 效果: 爬虫始终获取实时内容,索引延迟降至最低(接近无CDN状态)。普通用户请求仍享受缓存加速。这是目前解决索引时效性最彻底、最高效的方案。
- 步骤:
-
构建动态内容分级缓存体系:
- 步骤:
- 分析网站内容类型及其时效性要求(新闻/博客<分钟级,产品详情<小时级,帮助文档<天/周级)。
- 在边缘节点部署逻辑,根据URL模式、内容类型或API响应动态设置差异化的
Cache-Control头部。 - 对极端敏感内容(如限时抢购页面),可设置
max-age=0或no-cache,但仍需结合爬虫旁路确保爬虫理解。
- 效果: 在满足核心内容即时索引的前提下,最大化整体缓存命中率,减轻源站压力。
- 步骤:
-
集成缓存标签与自动化刷新 (Cache-Tag & Auto-Purge):
- 步骤:
- 在源站生成内容时或边缘节点响应时,为缓存对象附加细粒度标签(e.g.,
X-Cache-Tag: product_789, category_electronics)。 - 当内容在后台更新时(如CMS发布、库存变更),调用CDN Purge API,仅清除包含特定标签(如
product_789)的缓存项。 - 利用边缘计算,可将Purge请求高效广播到所有相关节点。
- 在源站生成内容时或边缘节点响应时,为缓存对象附加细粒度标签(e.g.,
- 效果: 实现精准、即时的缓存失效,确保用户和爬虫访问到的都是更新后内容,避免了全站Purge的性能冲击。
- 步骤:
-
利用
stale-while-revalidate与stale-if-error策略:- 原理: 这些HTTP缓存扩展指令允许边缘节点在后台异步验证过期缓存的同时,先返回一个“陈旧但可用”的响应给用户。
- 边缘SEO优化: 对爬虫请求禁用此行为! 确保爬虫要么获得新鲜内容(旁路回源),要么明确获得过期指示(触发其重新抓取)。普通用户则可受益于更快的响应和更好的容错。
- 示例配置:
Cache-Control: max-age=600, stale-while-revalidate=30, stale-if-error=86400。但对爬虫的请求,边缘逻辑应覆盖为max-age=0或强制回源。
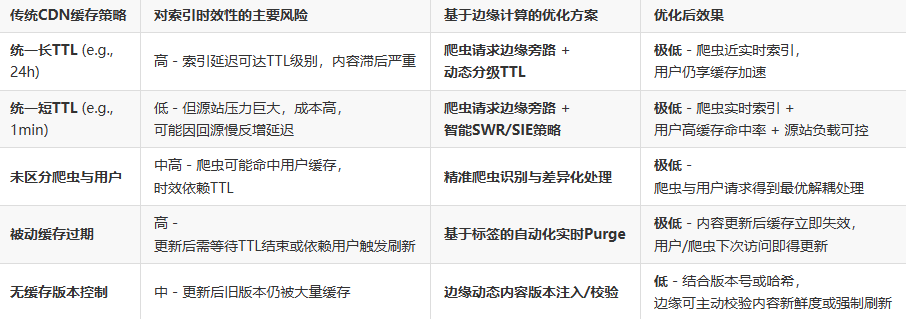
CDN缓存策略对索引时效性影响及边缘优化方案对比表
五、实践中的关键考量与陷阱规避
- 爬虫识别可靠性: 伪造User-Agent简单。务必结合IP反向DNS验证(如验证
xxx.xxx.xxx.xxx的反向DNS是否匹配*.googlebot.com)或使用CDN/云服务商提供的可信爬虫列表API。误判将导致缓存旁路滥用,增加源站压力;漏判则无法解决索引滞后。 - 缓存污染 (Cache Poisoning): 差异化处理爬虫时,确保边缘逻辑不会将爬虫获取到的特定响应(如带调试信息、不同布局)错误缓存并返回给普通用户。严格隔离爬虫回源响应与用户缓存。
Vary头的正确应用: 如果对爬虫和普通用户提供显著不同的内容(不推荐,除非有强理由),必须设置Vary: User-Agent。但注意这可能导致缓存碎片化,降低命中率。优先采用内容一致,仅处理方式(旁路)不同。- 源站更新与边缘Purge的原子性: 确保在源站内容成功更新之后再触发CDN Purge。避免出现内容未更新但缓存已清空,导致用户/爬虫获取到错误中间状态或404。
- 监控与告警:
- 监控爬虫旁路比例是否异常高(可能遭遇爬虫攻击)。
- 监控CDN缓存命中率变化,确保优化未意外破坏用户缓存效率。
- 监控索引速度指标(Google Search Console索引覆盖率报告、索引延迟测试)。
- 设置源站负载告警。

六、未来展望:边缘计算驱动的主动式SEO
边缘计算赋予SEO前所未有的主动性与控制力:
- 边缘预渲染 (Edge Prerendering): 识别高潜力爬虫请求(如访问重要新内容或更新页面),在边缘节点主动执行轻量级渲染(甚至预取关联资源),将完全渲染好的HTML快速返回给爬虫,极大提升爬虫效率与索引速度。
- 实时边缘日志分析与爬虫行为优化: 在边缘节点实时分析爬虫访问模式、遇到的错误(404, 5xx)、渲染问题,并即时调整网站结构、返回友好错误信息或触发内容刷新,引导爬虫更高效工作。
- 个性化内容与SEO的融合: 在边缘根据用户信号(或爬虫类型)动态微调页面SEO元素(如规范链接、微数据、内部链接权重),同时确保核心内容索引的一致性,探索更智能的SEO适配。
结论:拥抱边缘智能,化解缓存与索引的时效性困局
CDN缓存不再是SEO索引时效性的“天敌”,边缘计算已将其转化为可控变量。通过实施精准的爬虫请求边缘旁路、构建动态分级缓存策略、利用标签化实时刷新机制,我们能够近乎完美地平衡网站性能(用户访问速度)与搜索引擎可见性(内容即时索引)这对传统矛盾。
作为SEO从业者,理解CDN的缓存机制是基础,而掌握边缘计算平台提供的动态处理能力,则是实现下一代高效、健壮SEO架构的关键。这要求我们跳出单纯的关键词研究和链接建设,深入基础设施层,与开发运维紧密协作。我亲眼见证并实践了这些策略带来的显著成效——新闻客户的索引延迟从小时级降至分钟级,电商平台的产品更新几乎实时出现在搜索结果中,同时源站负载保持健康。边缘计算驱动的SEO优化,正从技术前沿走向必备实践。未来,唯有持续拥抱基础设施的智能化变革,才能在搜索引擎可见性的竞争中保持领先地位。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。