一、开篇导读:搜索引擎“看不到”的页面,才是真正的流量黑洞
我们在日常做SEO时,总习惯看索引数、抓取频率、Search Console中可见的“表层指标”。但实际中,真正导致网站流量损耗、页面权重积压、转化机会断裂的元凶,往往不是“内容差”,而是搜索引擎压根没看到的页面——也就是被爬虫遗漏的关键页面。
在我最近一次为某大型电商网站进行爬虫优化时,通过完整分析其30天内的日志文件,我们识别出一批被完全跳过或极少访问的核心页面,占比约20%,却包含了数百条高价值商品、专题页、品牌长尾词。
本文就是基于我对真实日志文件的深度分析经验,系统复盘这一过程:如何从混杂的服务器访问记录中筛选出“被忽略”的页面?又如何通过可执行的步骤将这些页面重新送入搜索引擎的视野?

二、日志文件在SEO中的真正价值:比Search Console更“深层”
日志文件是网站服务器记录下的所有请求访问记录,包括:
- 爬虫访问记录(Googlebot、Bingbot等)
- 用户访问记录(UA、IP)
- 返回状态码(200、301、404等)
- 访问时间戳
- 访问频率和路径结构
我之所以重视日志文件,不是因为它“技术感强”,而是它提供了未被Search Console揭示的真相。具体来说,它能解决以下三个SEO死角问题:
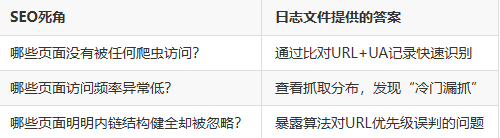
三、识别遗漏页面的完整流程:从“海量记录”到“精准定位”
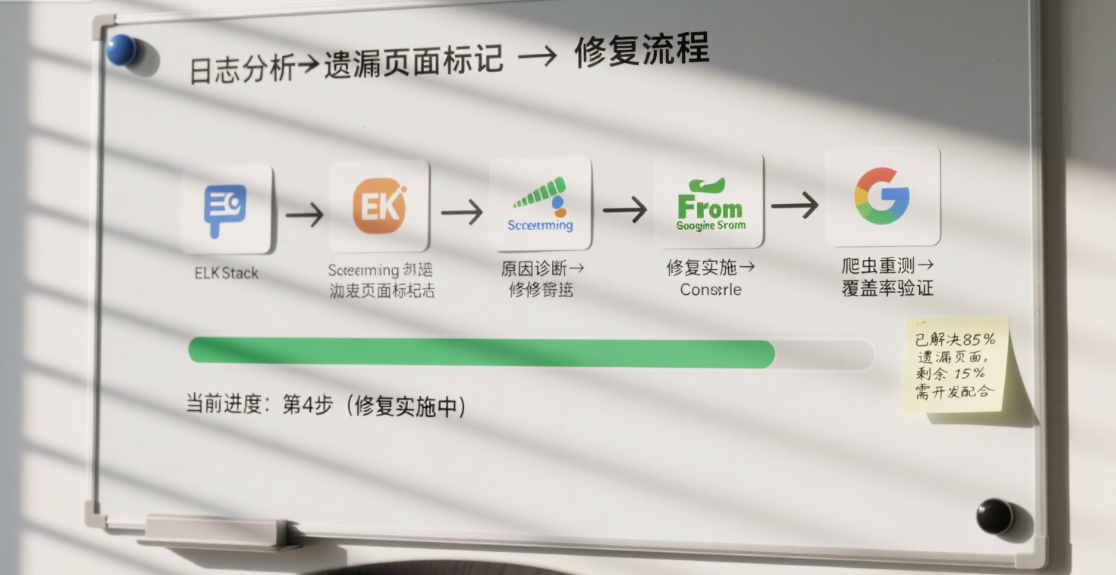
我的整个分析流程包含六个步骤,从日志清洗到页面修复,一套下来即可构建网站“爬虫关注度地图”,如下图所示:
3.1 步骤一:提取搜索引擎爬虫的访问记录
首先从日志文件中筛选出搜索引擎爬虫的访问条目,核心是UA字段(User-Agent):
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)我用Shell+Python做批量过滤,然后按访问日期分组整理出每个爬虫在每一天的抓取路径。
实战技巧:不要只看Googlebot,还应监控Bingbot、AhrefsBot、SemrushBot,它们同样反映市场抓取趋势。
3.2 步骤二:构建“全站URL基线”
你必须有一个完整的全站URL集合用于比对:
- 从数据库导出已发布URL列表
- 或者用Screaming Frog/Xenu全站扫描
这一步是后续识别“从未被抓取”页面的前提。我的经验是,只有全面掌握站内URL结构,才能发现真正被遗漏的页面。
3.3 步骤三:日志对比识别“从未访问”页面
通过对比“已发布URL”与“日志中出现过的URL”这两个集合,得出差集,即:
未出现在日志中的URL = 潜在被遗漏页面这些页面要么:
- 权重低,被搜索引擎跳过
- 内链结构太深
- robots.txt屏蔽
- 存在canonical指向问题
我一般会将这些差集按类型归类(例如商品页、文章页、专题页等),再根据业务价值做优先级排序。
3.4 步骤四:识别“抓取频次极低”的页面
被遗漏不一定是“完全没来过”,还有一类是:
- 7天只抓取1次
- 月度访问不足2次
- 与同类页面相比显著偏低
我会把所有URL按路径类型分组,然后计算访问频次分布百分位,低于第20百分位的,我全部打标为“抓取频次低”。
特别提醒:频次低≠页面不好,很多是结构位置不优、链接未覆盖、锚文本弱等问题导致。
3.5 步骤五:交叉验证内链结构与robots规则
我将“被遗漏页面”反查其在站内的链接数量与位置分布,有三个高频场景:
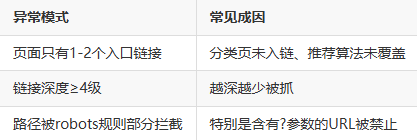
此时需将robots.txt规则与sitemap路径结构对照校验,确保高价值路径不被误伤。
3.6 步骤六:标注索引状态进行验证闭环
识别只是第一步,下一步要通过Search Console、site:语法等手段验证这些页面的实际索引状态,我的做法如下:
- 用URL批量提交索引工具检查状态(是否已收录)
- site:搜索+intitle关键词进行近似验证
-
将结果归类为:
- 未抓未收录(重点修复)
- 偶尔抓取但未收录(结构优化)
- 抓取正常但收录慢(内容弱)
四、20%关键页面的修复流程与策略打包
日志分析完成后,我会按以下三条主线制定修复计划:
4.1 内容结构优化
- 将深层页面纳入“相关推荐”模块
- 用内部锚文本加强它们的主题相关性
- 控制段落文字结构,增加首段权重关键词
4.2 内链引导与URL布局重构
- 把被遗漏的商品页或专题页链接到首页/核心分类页
- 调整分页逻辑,让爬虫在前3层抓完所有重要页面
- 合理使用面包屑导航,增强路径可追溯性
4.3 robots.txt与sitemap同步校验
- 确保参数页面不被整体屏蔽(用clean-param控制而非全禁)
- sitemap需每日更新,并提交新的高优先级路径
- 对canonical链接进行反查,确保指向本页或内容聚合页,不跨意图指向
五、实战效果反馈与数据成果
以下是我最近两个项目的日志分析+修复带来的效果:

这些提升并非来自内容新增,而是对**“被忽视资源”的回收利用**。
六、构建可持续的爬虫监测系统
我不建议只在问题出现时分析日志,而是构建一个持续日志监测体系:
- 每周自动抽取前7天抓取频次top/bottom页面
- 每月生成一次未访问页面清单
- 出现抓取频次下降的页面自动标记并加入内容审查计划
我用Python配合Elasticsearch可视化日志流,让SEO团队能像数据运营一样,定期“体检”爬虫行为。
结语:SEO真正的增长空间,不在内容新增,而在索引回收
通过这几年日志实战,我越来越确信一点:
搜索引擎看不见的页面,等于白写;抓不到的路径,等于失联。
日志文件分析不是技术炫技,而是让我们跳出“优化可见页面”的思维误区,进入**“修复看不见的价值”**的深水区。20%的被遗漏页面,可能承载着80%的潜在流量回收空间。
如果你今天开始分析服务器日志,你会发现,那些你以为不重要、或者从未纳入搜索引擎视角的页面,正是你流量突破的关键盲点。
霓优网络科技中心是一家专注于网站搜索引擎优化(SEO)的数字营销服务提供商,致力于帮助企业提升网站在搜索引擎中的排名与收录效果。我们提供全方位的SEO优化服务,包括关键词策略优化、内容质量提升、技术SEO调整及企业数字营销支持,助力客户在竞争激烈的网络环境中获得更高的曝光度和精准流量。