一、引言:搜索引擎理解网站内容的“信号灯”
在现代SEO优化中,内容创作与页面布局已不是唯一关注点。如何指导搜索引擎理解、抓取、索引你的网站内容,才是掌控排名主动权的关键。正如交通系统中需要红绿灯调度秩序,网站也需要一种机制来告诉搜索引擎哪些内容应当被索引、哪些链接可以信任、哪些页面应当忽略。这种“沟通语言”就是Meta Robots标签。
尤其对于大型站点、内容密集型平台、电商系统等,合理使用noindex与nofollow指令,不仅能提升收录效率,还能避免权重浪费、降低内容重复度、规避无效流量干扰。本文将从原理、语法、应用场景到策略建议,系统解析Meta Robots标签及其核心指令noindex、nofollow的实际作用。
二、Meta Robots标签的基础定义与核心功能
2.1 什么是Meta Robots标签?
Meta Robots标签是一种HTML元标签(Meta Tag),位于网页 <head> 区域,用来控制搜索引擎对该页面的抓取与索引行为。
基本语法格式如下:
<meta name="robots" content="index, follow">2.2 Meta Robots的两个核心维度
Meta Robots标签控制搜索引擎两件事:

三、Meta Robots指令详解:noindex与nofollow的区别与联系
3.1 noindex的含义与作用
✅ 定义:
当你希望页面不被搜索引擎收录,不参与搜索排名时,使用noindex。
✅ 示例代码:
<meta name="robots" content="noindex, follow">✅ 实际作用:
- 页面不会被索引,不会出现在搜索引擎结果中;
- 不会传递关键词排名;
- 页面仍然可以被抓取,只是不被展示;
- 页面上的链接仍然会被“跟随”,除非加上
nofollow。
✅ 使用场景:
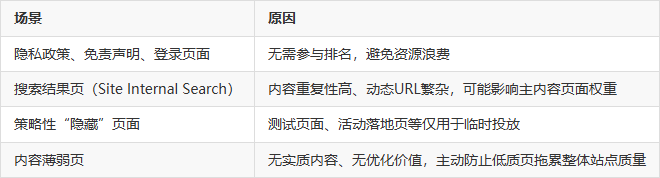
3.2 nofollow的含义与作用
✅ 定义:
当你希望搜索引擎不要抓取页面内的链接,也不传递权重到这些链接,就使用nofollow。
✅ 示例代码:
<meta name="robots" content="index, nofollow">✅ 实际作用:
- 搜索引擎不会“信任”页面中的外链;
- 链接不参与PageRank(排名权重)的传递;
- 对链接目标页面的排名无帮助;
- 页面本身仍然可以收录。
✅ 使用场景:

四、常见Meta Robots指令组合及其含义对照表

五、Meta Robots与其他抓取控制方式对比(表格详解)

⚠ 注意:Meta Robots标签与Robots.txt文件的逻辑冲突时,Robots.txt优先影响抓取行为,Meta Robots控制是否索引。若Robots.txt禁止了访问,搜索引擎将无法看到Meta Robots标签,自然也无法执行其指令。
六、Meta Robots标签的正确使用策略
6.1 对不同类型页面的使用建议

6.2 配合Canonical使用,解决重复内容问题
对于结构相似、内容接近但必须保留的页面(如分页、筛选组合),应优先:
- 设定主版本页面为
index, follow,同时添加<link rel="canonical"> - 次要版本页设为
noindex, follow或noindex, nofollow
这样可防止搜索引擎索引重复内容,又能保留内部链接价值。
6.3 动态设置Meta Robots:CMS平台技巧
多数内容管理系统(如WordPress、Shopify、Magento)支持在后台为页面设定Meta Robots标签。
- WordPress可用插件如 Yoast SEO、RankMath 控制每篇文章的索引指令;
- 对于电商页面,建议通过模板文件自动为无库存商品添加
noindex; - 可配合数据库标记、URL参数逻辑,动态生成Meta Robots标签;
七、Meta Robots的实际误区与风险案例
7.1 忘记撤销noindex导致收录下降
常见于测试阶段上线时设置了noindex,上线后忘记改回。结果页面长时间不被收录,流量骤降。
✅ 解决方案: 配合Google Search Console排查非收录页面原因,确认是否因noindex所致。
7.2 错误使用noindex, nofollow于栏目页
很多站点担心栏目页内容薄弱,就直接将其设为noindex, nofollow,结果导致栏目页无法传递权重至内容页,内部链接结构断裂。
✅ 建议: 采用noindex, follow,保留链接价值。
7.3 配合robots.txt屏蔽,又添加Meta Robots控制
如果你在robots.txt中已经阻止搜索引擎抓取某目录,如:
Disallow: /private/但又在该目录页中设置了:
<meta name="robots" content="noindex, follow">此时,Google连页面都无法抓取,自然也看不到Meta Robots标签,指令失效。
✅ 正确做法: 若希望搜索引擎抓取但不索引,请不要在robots.txt中禁止,而是通过Meta Robots控制。
八、Meta Robots标签配置流程(Checklist)

九、总结:掌控抓取与索引的核心机制
Meta Robots标签是Google SEO中精细控制页面表现的重要工具,尤其在大规模网站管理中,更显其战略价值:
noindex控制搜索引擎的“可见性”;nofollow控制链接权重的“流向性”;- 合理配置,能显著优化爬虫资源分配、收录效率与站点权重流动;
如同SEO的“分流阀”,Meta Robots标签决定了哪些内容能够参与排名竞争,哪些链接可以信任、传递价值。掌握它,就掌握了搜索引擎眼中的网站结构权重图谱。
如需进一步生成针对你网站结构的Meta Robots配置策略,欢迎告诉我你的网站类型和页面分布,我可以为你制定细化的标签配置逻辑表。