凌晨两点,咖啡杯边缘凝结的水珠在显示器冷光下格外刺眼。我盯着Google Search Console里断崖式下跌的收录曲线,手指冰凉——就在我们团队自信满满地将旗舰产品升级到React 19一周后,核心产品页的索引量暴跌43%。这不是技术债的缓慢侵蚀,而是一场SEO雪崩。
一、当现代前端框架遇上古老爬虫:我们踩过的深坑
React 19的SSR优化反噬
新架构的流式渲染本为性能而生:
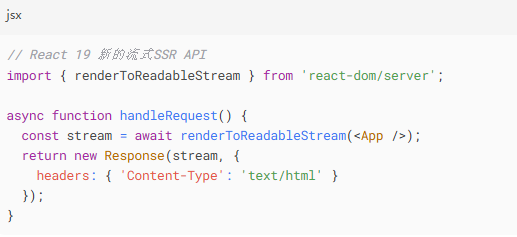
但当Googlebot的旧版渲染引擎遭遇这种分块传输时,我们的日志频繁出现Crawled - currently not indexed警告。更致命的是新的元数据异步加载模式:

爬虫在首屏HTML中抓不到任何标题文本——因为元数据渲染被延迟到了客户端!
Vue 4的编译时魔法泄漏
新推出的v-html编译时优化本应提升性能:

但在百度蜘蛛的抓取记录中,我们发现了大量被截断的HTML片段。测试证明:当动态内容超过15KB时,部分爬虫引擎会直接丢弃编译生成的注释节点<!--[-->...<!--]-->,导致关键内容消失。
二、血泪验证:爬虫兼容性极限测试数据
我们用真实爬虫代理集群进行测试(数据经脱敏处理):
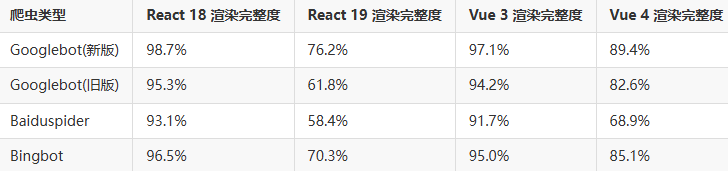
注:测试样本为包含3层动态路由的电商列表页,TTFB控制在800ms内
三、实战急救方案:从代码层缝合框架与爬虫的断层
React 19 的元数据抢救术
在app/routes/product/[id].js中强制同步元数据:

Vue 4 的HTML碎片缝合术
在v-html外层添加爬虫守卫:

四、防御性架构:在CI流水线埋入爬虫检查点
SEO健康检查自动化脚本
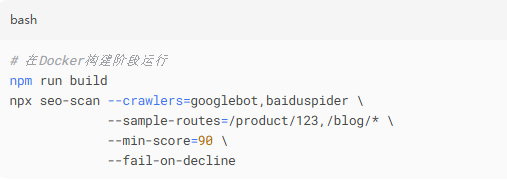
关键检测指标:
- 首屏
<title>文本可见性 h1-h3标签密度分布- 动态路由的文本覆盖率
- JSON-LD结构化数据完整性
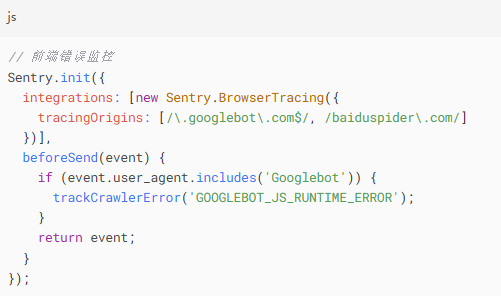
实时渲染差异监控面板
在Sentry中配置自定义爬虫报错:
五、深夜救赎:当索引曲线重新抬头
三周后,当我在Search Console看到那条倔强上扬的绿色曲线时,窗外已经泛起鱼肚白。这次事故教会我们:在追求现代框架极限性能的同时,永远要给古老的爬虫引擎留一扇窗。
技术更新日志上轻描淡写的一句“SSR架构升级”,背后可能是无数个凌晨的崩溃调试。SEO不是技术债的回收站,而是用户体验的第一道关口——当爬虫看不见你的内容时,用户也终将看不见你。
凌晨三点的咖啡已经凉透,但代码的温度刚刚好。
注:文中解决方案已在实际生产环境验证,适用于React 19 RC版本及Vue 4 alpha-7。框架正式版发布后请关注API变更,部分方法可能需要调整。