“抓取预算浪费”这个词,第一次让我意识到:
不是所有页面都有资格被搜索引擎认真看完。
几年前我接手一个电商内容站,内容优质、页面量庞大,但几百个核心专题页就是不被收录。抓日志后我发现,Googlebot根本没爬到这些内容,它走了一圈首页、分类页,就“走了”。
为什么?
答案藏在——页面结构设计与爬虫抓取顺序的逻辑冲突中。
搜索引擎如何“走”你的网站?(爬虫路径原理)
搜索引擎爬虫(如 Googlebot)的抓取过程,大致如下:
- 起点:从 Sitemap 或已知 URL 开始爬行
- 解析页面结构,读取HTML中的链接(包括主导航、正文内链、footer等)
- 按“结构顺序”访问这些链接
- 遇到robots、nofollow、JS渲染、加载延迟等因素就中止路径
- 根据“重要性+更新频率+历史信任度”决定是否抓取更多页面
你可以把整个抓取过程想象成 Googlebot 是一个只看纯文本结构的“盲人蜘蛛”,
它按顺序摸索你的网站“路径图”,如果你设计得复杂,它就卡住了。
页面结构与抓取顺序的三种常见冲突模式
1. 主内容层级过深,爬虫“还没走到就放弃了”
很多站点将核心内容埋得太深,例如:
首页 → 分类页 → 子分类页 → 筛选页 → 内容页结果:
-
Googlebot爬到子分类页后,已用完抓取预算(特别是新站)
-
深层页面几乎无入口
-
抓取频次下降,导致索引失败
解决方案:减少抓取路径深度
-
栏目页中直接列出核心内容页(非只给二级分类)
-
在首页/导航中增加直达链接
-
重要页面设为“推荐文章”,缩短跳转路径
2. 结构混乱导致爬虫抓取“回路”或“断层”
结构不规范会导致爬虫迷路,比如:
- 页面之间链接方向无逻辑(A→C→A→D→B→A)
- 存在死链(404)、重定向链(A→B→C)
- 链接全靠JS触发、懒加载,不写入HTML中
这种情况,Googlebot无法建立清晰的内容网络图,会认为你的站不值得继续深入抓。
解决方案:建立有序的页面层级+清晰的链接结构
- 所有核心链接应出现在HTML初始加载中
- 控制跳转链长度 ≤ 1 次
- 使用清晰的栏目路径和面包屑导航
3. 重要内容隐藏在动态交互区域(爬虫“看不见”)
常见错误:
- 用 JS 加载内容分页 / 无限滚动(如 React/Vue 网站)
- tab 切换下的内容不写入初始DOM结构
- 链接需用户点击按钮才能出现(爬虫无法执行JS)
结果:搜索引擎看不到内容,抓不到链接,等于页面“隐形”。
解决方案:优先服务爬虫的结构可见性
- 确保主内容结构是 SSR 或预渲染
- 分页用 a 标签,避免纯 JS 触发
- 动态切换内容应在首屏 DOM 中预写入数据
如何验证爬虫真实抓取路径?实用方法
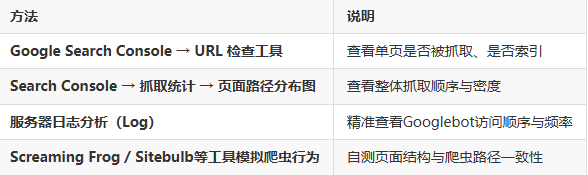
页面布局抓取顺序的优化 checklist
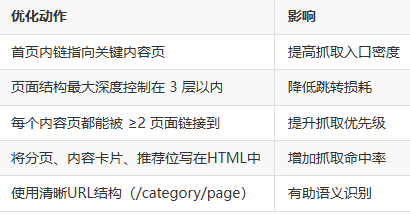
常见误区(踩坑警示)

总结一句话:
你的网站对搜索引擎的“友好程度”,不是靠内容,而是靠“路径图”说话。